CSE 373 Assignment 3
Due April 21 2000
This is a programming assignment, and so you must follow all the guidelines
specific to programming assignments.
| You will implement a new data structure, called a
Split. (This is not a standard name or a standard data structure.) A
Split is like a binary search tree for two-dimensional data. For
example, suppose you have a bunch of cities on a map, and want to be able
to look up a city based on its (x,y) coordinate, and perhaps find some of
its neighbors. A normal list or binary search tree isn't much help here
because the data has no natural linear ordering. You could try
ordering by one coordinate or the other, but then nearby cities could be
far away from each other in the data structure.
We will create a tree structure that has four children per node,
instead of the two children we were used to with binary search trees. A
node will either be a leaf (containing info about one city), or a
"split" node. Split nodes represent a rectangular area on the
map, and the four children correspond to the four quadrants of that
rectangle.
Note that this is slightly different from the way binary search trees
work, because here all the data is in the leaves. Interior split nodes
have no city data.
|
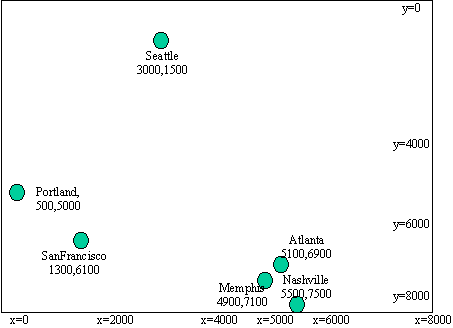
Figure 1: a map containing several cities
|
| In figure 2, we have divided the map into four large
sections. These four sections are the children of the root node in the
tree. The upper right node has no cities, so that pointer will be null.
The upper left node has one city (Seattle), so that child pointer will
point to a leaf node representing Seattle.
The lower left section of the map has two cities (Portland and
SanFrancisco). A single leaf node isn't enough, so we divide that section
into 4 subsections. The root's lower-left child pointer will point to a
split node (call it LL). LL has four children of its own; two of
them are null (the upper right and lower right) and two are leaves (upper
left and lower left).
How did we decide the way in which to split up the map? A very
simplistic method is used -- whenever you need to split a section because
you have more than one city there, divide the section right down the
middle (both in x and y). You'll note that the split in the lower
right (the lines are at x=6000, y=6000) didn't accomplish much. The
three cities are still all in one section after that first split, and
another split was necessary to separate them.
|
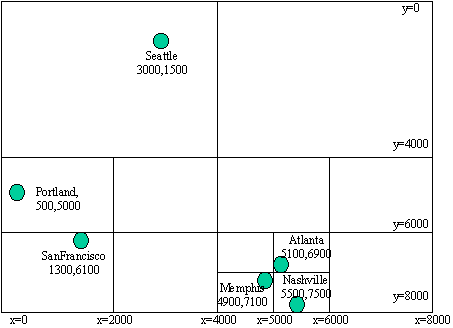
Figure 2: a map that has been split |
| It would have been better to split the lower right section
at x=5000, y=7000, as shown in figure 3.
However, this would require more smarts than we will have time
for. Using the data to decide where to split is known as an adaptive
technique (the data structure "adapts" to different input data).
|
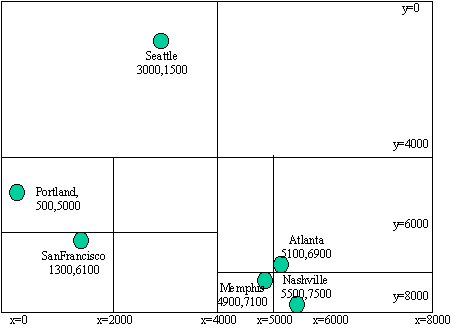
Figure 3: a more efficient way to do the split--we will not try to
do this!!
|
Here is a more direct representation of the tree structure for the example in
figure 2.
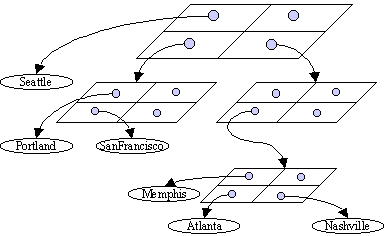
You are given the following files:
- split.h:
declarations of structures and various functions. You are not allowed to
change anything in this file
- split.cpp:
skeleton code for the ADT. The main( ) routine is provided, as well as a
number of support routines (such as dump). You will write the core
operations, as marked by TODO comments in the code.
- split.txt:
a sample input file
There is also a sample
solution provided so you can see what is supposed to happen.
The split.txt file consists of a list of data and commands, with a fixed
organization. Each line must contain two numbers (x and y coordinates) followed
by a string. The contents of the string determine what the line will do:
- DUMP will print out the tree, ignoring the x and y values on this line
- FIND will search the tree for a city at the provided (x,y) coordinates
- REMOVE will remove the city, if any, at (x,y)
- any other value will be treated as a city name and inserted into the tree
at (x,y)
Here is an outline of the provided structures, and what each function you
write must do.
The split node structure
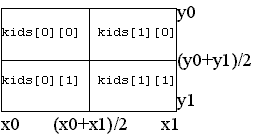 A
split node contains 4 child pointers, arranged in a 2 by 2 array named kids.
Using an array instead of four separate data fields allows us to use looping
when we need to scan through all four children for some reason, instead of
having to write the same code four times.
A
split node contains 4 child pointers, arranged in a 2 by 2 array named kids.
Using an array instead of four separate data fields allows us to use looping
when we need to scan through all four children for some reason, instead of
having to write the same code four times.
Each split node also stores the rectangle of the map that it covers. The
fields x0, x1, y0, y1 determine the edges, as shown. Midpoints must be
calculated when needed. For example, any city at position (x,y) where x0 <= x
< (x0+x1)/2 and where (y0+y1)/2 <= y < y1 falls in the lower left
section. To find or insert this city, we would need to visit the kids[0][1]
child.
Note that I've used a single structure to represent both types of nodes (leaf
and split). Simply ignore the data fields that don't apply, as described in the
comments.
char *Find(PtrToNode pn, int x, int y)
As always, Find is the easiest function. It returns the city name at (x,y) if
there is one, or NULL if not. Every split node contains four numbers which
determine what rectangle the node is responsible for as described above. The
find_child( ) function uses these numbers to determine which child pointer would
be responsible for the city. As you travel down the tree, you will eventually
hit either a null child (a failed Find), or a leaf node child (a successful
find).
PtrToNode Insert(PtrToNode pn, int x, int y, char *name, int x0, int x1, int
y0, int y1)
Given the root of some subtree pn, Insert finds the appropriate spot to add a
new leaf node, splitting if necessary. A recursive function will be easiest to
write. Keep scanning down any split nodes as you do for a Find. If you hit a
null pointer, you can just create the leaf node and insert it there. If you hit
a leaf node, you will need to create a new split node and add both the old and
new cities to that split node (use calls to Insert to do this).
The last 4 parameters are the bounds of the rectangle corresponding to this
node. If the current node is a split, this info is redundant since it is already
stored in the split node. However, if the current node is a leaf, you will need
this info in order to initialize the new split node you create--otherwise we
wouldn't know. Thus, you must calculate the new bounds each time you visit a
child pointer of a split node, using the get_coords( ) function.
Insert returns a pointer to the subtree pn after the insertion. The caller
should overwrite their old pointer with the returned value, because the root of
the subtree may have changed. (Specifically, if the old subtree was a leaf, the
new subtree will have a split node at the root instead.)
PtrToNode Remove(PtrToNode pn, int x, int y)
Removes the city at (x,y) from the subtree pn, if it exists. Returns the new
root of the subtree. There are special cases to consider here.
- If pn is a leaf and matches (x,y), deallocate it and return null
- If pn is a split, figure out which child would contain (x,y) and recurse.
Overwrite that child pointer with the return value of the recursion.
If Remove returns null, we may also need to remove the current node. If the
current node is a split node and has no children left, deallocate it and return
null. If there is exactly one child left, and it is a leaf, we can
deallocate the split node and return the leaf node. This will bump the leaf node
one level up the tree. Note that you can't do this if the single child is a
split! You would actually lose coverage of part of the tree, possibly causing
future inserts to fail.
int ComputeSplitSize(Split S)
Recursively go through the tree, counting how many cities (leaf nodes) there
are.
I have provided several helper functions which will significantly reduce the
code you have to write. Take a look at the .cpp file and see what is available
to you. You don't want to rewrite all that code, so read the skeleton file
carefully before you start coding.
Tips
Make generous use of the dump( ) function. Call it before and after every
step if you have to, so that you can see exactly where your bugs are happening.
You can add lines saying "0 0 DUMP" to your input file without having
to recompile the program.
Get all the functions working with just leaf nodes to start. You'll only be
able to create one-node trees, but it's a first step.
Then, I'd suggest doing Insert, Find, and Remove in that order. You should
find Remove to be fairly easy after having written Insert.
Start early so you can get help from the TAs! It's much easier to get live
help than try to explain your problem over email.