
The late David Huffman
5/27/00, Due Monday 6/5/00, no lates accepted
|
The late David Huffman |
Huffman encoding is a simple technique we've studied to compress a file or a message sent over a network. However, it has the disadvantage of requiring two passes; one to compute the character statistics and build the tree, and one to do the encoding. If you are CNN, broadcasting a continuous stream of news or stock data, you don't have a complete file that you can pre-scan. You need a way to take the bytes as they arrive and do your best. Another disadvantage of "static Huffman" is that decoding information must be prepended to the file, which is a lot of overhead for small files.
Adaptive Huffman encoding is a one-pass compression algorithm which builds the tree on the fly, at the same time as it encodes individual characters. The encoder and decoder both begin in a known state and stay in sync as each bit of information is transmitted. The pseudocode is as follows:
| Encoder:
|
Decoder:
|
Unlike static Huffman, a single symbol such as 'A' will be encoded with different bits at different times, since the tree changes as more frequency data is obtained from the input stream. The encoder and decoder must be carefully written to change the tree in exactly the same way, so that the decoder can understand the bit stream coming from the encoder.
A simple way to implement this would be to keep track of frequency information, and rebuild the tree from scratch after each character. We know how to build a tree from scratch--it's just static Huffman encoding, as we learned in class. Of course, this seems like a wasteful way to do it, and there is indeed a more efficient technique.
Take a look at the following simple Huffman tree, which codes for the symbols 'a', 'b', 'c', and a special symbol NYT we'll talk about later.
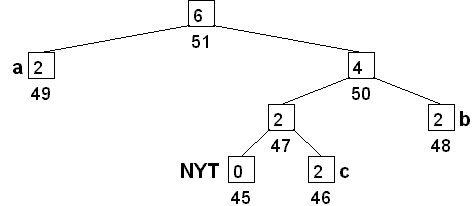
The weight (frequency) is shown inside each node. The numbers below the nodes are something new. In this case, they represent a reverse level-ordering of the nodes. If you construct a Huffman tree in a certain careful way, the nodes satisfy a special property:
If node x has a greater weight than node y, then the node number for x is greater than the node number for y.
This property is the key to efficiently updating the tree. Whenever we make a change that would violate the property, we know that we need to move some nodes around to fix things up. In the example, suppose the next symbol was a 'c'. We can't just update c's weight to 3, as that would violate the sibling property (node 47 would have a lower weight than node 46). What we need to do is swap 'c' with 'a', and then update c's weight.
If this were a normal binary tree, we'd be in trouble since there's no obvious way to get from 'c' to 'a'. The node numbering makes it possible. The nodes are kept in an array. Each node points to its parents and children using array indices (e.g. the root will have children 49 and 50). Now, when we look at node 'c', we can just scan up the array looking for other nodes with weight 2, and swap with the last one we find. If we don't find any (the usual case once the tree has some stuff in it), then no swap is needed.
The contiguous set of nodes with the same weight is called a block. In the example, the weight-2 block is nodes 46 to 49. If any node in the block is to be incremented, it should first be swapped with node 49.
Note: if the only other node with the same weight is your parent, you should not swap. This can happen because the special NYT node has weight zero, so 'c' and its parent have the same weight.
There are 258 possible symbols (256 byte values plus NYT plus ENDOFFILE). A Huffman tree never needs more than twice this amount of total leaf+internal nodes. Begin by making the last array element the root of the tree; it will be the NYT node.
Because the NYT node always has a weight of zero, it will always have the lowest node number. When you get a new symbol, you can use the next two lower node numbers for the two new nodes (n-2 for new NYT, n-1 for new symbol). This will keep all the nodes contiguous.
Each node needs to point to its parent (used when encoding) and to its children (this direction used when decoding).
In addition, you need a way to find which leaf node corresponds to a certain symbol. This is done with a separate symbols array. Each element points to the leaf node for that symbol. The symbols array also tells you whether a certain symbol is in the tree at all. For example, symbols['A'] should contain an index for some node if 'A' is in the tree, or the special NONE value if not.
To encode a symbol, find the leaf, then follow parent pointers to the root. At each step, the isLeftChild member is a convenient way to decide whether the bit should be a zero or one.
To decode bits into a symbol, start at the root of the tree. Each bit tells you which direction to travel in the tree. When you reach a leaf node, you can output the symbol.
Suppose the next symbol to send is a 'd' in the example. The symbol isn't in the tree yet, so we don't have a code. We can't just add 'd' to the tree and transmit the new code, because the decoder won't have any idea that there was a new code or what the symbol is.
Whenever a new symbol is found, we send a special "escape" character (called UNKNOWN in the code, or NYT "not yet transmitted" in the example). This alerts the decoder that something new is coming. Then, we send the raw byte for the new symbol. The decoder now knows what the next symbol is. Finally, both encoder and decoder add the new symbol to the tree. It will have a weight of 1.
In order to maintain the sibling property, the new symbol needs to be at the bottom of the node ordering. We do this by splitting the NYT node into two children. The original node will become an internal parent node. The left child will simply be the new NYT node; we can just copy the node info down. The right child will be the node for the new symbol.
We now have the following outline for updating the tree after each symbol is seen.
if it's a new symbol
split the NYT node into two children, both with weight zero
increment the weight of the symbol's node
before incrementing, swap with the last node in current block
(unless its your parent)
recursively increment weights of parent nodes, all the way to
root (swap as necessary)
The system we're using may cause more than one swap after a single symbol is updated. There are variants of the algorithm that guarantee at most one swap after each symbol.
As mentioned in class, since the compressed data doesn't fall on byte boundaries, the decoder needs to know when to stop reading bits. A special ENDOFFILE symbol is added to the tree and output once at the end. The decoder should ignore any subsequent bits that come after this symbol. The encoder needs to output some extra padding bits in order to fill up the last byte--if you forget this you may not transmit the entire ENDOFFILE code.
We will add the ENDOFFILE symbol to the tree at the very beginning; its code will get longer and longer as the symbols get read in.
OK, the basic idea is quite simple and intuitive, but the details of tree manipulation are hard to imagine. The following applet gives a very good demonstration of how the tree is updated. (This excellent applet was written by D. Szupa.) Type your input in the box on the upper left. Refresh this page if you want to start over.
In our case, we will add ENDOFFILE to the tree at the very beginning, but we won't transmit the symbol. After that, our program should behave just like the applet. You can simulate this by typing in a special character (e.g. ` ) at the beginning to initialize the tree, and then proceeding with the actual symbol data.
The skeleton program handles three options on the command line, -d, -b, and -h.
I suggest you create a ReadBit and WriteBit function to hide the details of bit-level I/O. WriteBit will be used by the encoder. You should start by implementing the -b option, so that you can directly look at the output. Put a space after each code sequence, and after each 8-bit "raw symbol" that is sent. If the -h option is set, you should instead output the data in groups of 4 bits, with a space after every 4th and two spaces after every 8th. This will make it easier to compare the contents of a true binary file, since each 4 bit block corresponds to a hexadecimal digit (more on this below).
For example, if the input is "ABA", the output bits are:
0 01000001 00 01000010 11 11 00000000
These correspond to:
NYT 'A'(raw) NYT 'B'(raw) 'A' ENDOFFILE <8 bits of padding>
Note how the tree changes after the second 'A' so that the 11 code is now the code for ENDOFFILE.
Outputting "1" and "0" characters is nice for human readability, but it doesn't compress the file very well! We want to write a real compression program that actually generates a smaller file. To do this, we need to muck around with individual bits, something many of you aren't familiar with.
| 0000 | 0 | 0 |
| 0001 | 1 | 1 |
| 0010 | 2 | 2 |
| 0011 | 3 | 3 |
| 0100 | 4 | 4 |
| 0101 | 5 | 5 |
| 0110 | 6 | 6 |
| 0111 | 7 | 7 |
| 1000 | 8 | 8 |
| 1001 | 9 | 9 |
| 1010 | 10 | A |
| 1011 | 11 | B |
| 1100 | 12 | C |
| 1101 | 13 | D |
| 1110 | 14 | E |
| 1111 | 15 | F |
First a review of binary numbers. A byte contains 8 bits. That means there are 2^8 = 256 possible combinations. Counting in binary is like counting in decimal, just with fewer digits. Here are the first 16 numbers:
That third column is known as hexadecimal; it's a counting system with 16 digits. It's convenient because 1 hex digit is exactly equal to 4 binary bits, or 2 hex digits for one byte. You can open a binary file in MSVC (just select "Binary" in the "Open As" list) and it will show you the raw bytes as pairs of hex digits. You may find this useful when you're debugging.
Given a byte (i.e. an unsigned char), we can do things to the bits. Shifting slides the bits to the left or right. If you shift left, bits fall off the left edge and zeroes appear on the right. Shifting right is similar with one warning. You will get zeroes appearing at the left if your data type is unsigned. If you use a signed type (e.g. plain 'int'), you will sometimes get ones appearing at the left (if the current value is negative). This is not what you want for this assignment, so always use unsigned values.
The shift operators take a number of bits to shift. So, for example, 3<<2 == 12, and 11>>1==5.
The other thing you can do is mask. Sometimes you just want to know the value of one of the bits, or to set the value of one bit. This is done with the bitwise-and and bitwise-or operators. We usually use a hex value for the mask to make it clear that it's a binary mask. Hex values are written with a "0x" in front; for example, 0xFF is a byte of all ones, or 255.
To turn off bits you don't care about, use the & operator.
9 & 0x1 == 1. The rightmost bit of 9 is filtered out, and all
others are set to zero.
255 & 0x80 == 1. 0x80 is an 8-bit mask with only the left bit turned
on, so this filters out just that bit from a byte.
To turn a bit on, use the | operator. Suppose x = 6.
x | 0x1 will turn on the rightmost bit, resulting in 7.
x | 0xFF will turn all bits on, so you'll always get 255 no matter what x is.
You should hide all the bit manipulation inside ReadBit and WriteBit. You can't write a single bit directly, only single bytes. So WriteBit needs to accumulate individual bits in a holding variable until you get a set of 8; then you can use a function like putc(char, FILE *) to write the output to some file. You will need to use shifting and masking each time you get a new bit; for example, you could shift the old value left by 1 and use | to put the current bit in the low position. Just be consistent when you decode.
A good way to implement the holding variables is with the static keyword in C. If you declare a variable inside WriteBit as "static unsigned char c", that variable will keep its value across different invocations of the function. Each time someone calls WriteBit, your function can add the new bit to the existing value. This is cleaner than using global variables. Of course you'll also need a static bit count to tell you when you have 8 bits ready to go.
Similarly, you can only read a single character at a time (e.g. with the getc(FILE *) function). Your ReadBit function can hold the excess bits in a variable, and shift/mask one bit out at a time as needed.
Run the sample program with (the intermediate file is called tstenc):
huffsoln < inputfile
huffsoln -d > outputfile
I have provided a small dumpTree function in the skeleton. It does the usual thing of printing the tree sideways, with the root node to the far left.
I suggest writing small helper functions to read/write bits, raw symbols, and coded symbols. That way your main code can just invoke a high-level operation without worrying about the nasty bit-level details. An EncSymbol structure is defined for your convenience. It contains a code, and a count telling how many bits in the code variable are really part of the code.
Open your input files and output files in MSVC (choose Binary for Open As) to see the honest-to-gosh bytes. If you just use a text editor to create a sample file, sometimes odd extra characters sneak in. Binary I/O is scary since its so hard to check what's going on. Get your code working as well as you can before you start with the binary encoding/decoding.
You should wind up outputting exactly the same thing as the applet does, so use the applet to help you see where your code is going wrong. Use the dumpTree function to print out your tree and compare.
If you're having trouble with the binary encoding/decoding, first verify that your bit manipulation code works correctly. Try just "encoding" the file by doing nothing; just send the raw data through your bit functions. Next, try outputting a single bit (to shift everything over), and then sending the raw data again. If these both work, then your problem is likely in the Huffman part of the code rather than the bit-munging part.
In C, the getc(FILE *) function returns an int, not a char. That's because, in addition to all the valid char values, it can also return the special value EOF, for end of file. When you get this value, you know you're done. Of course, if you are encoding, you should send an ENDOFFILE symbol. If you are decoding a valid file, you should have stopped already before you get to EOF.
Good luck! I hope you enjoy this one.
The skeleton program is designed to encode by reading from stdin and writing to a file "tstenc". When decoding, it reads from file "tstenc" and writes to stdout. Use file redirection to read an input file or write decoded output to a file.
Commenting is worth 10% of the grade. If you're totally stuck, just get the -b option working, although this will be worth significantly less than full credit. Your program should behave just like the applet; the TAs will rely on this when checking results.
Turn in homeworks at the last class, or on Monday before 7 pm in Sieg 318. I won't be there during the day, so just slide your printouts under the door. Be sure to turn them in before 7! I won't keep going back to pick up stragglers.
Turn in your code online by emailing to morcos@cs and c373@ms.washington.edu before 7 pm on Monday. Use a subject line of "turnin hw7". DO NOT email your assignment to the class alias, cse373@cs. DO NOT!
As usual, you must do your own work. You can discuss general ideas with others, but you MAY NOT exchange code or look at another person's code. If you have a detailed discussion with someone, you must take a short break before going back to work (a half-hour of Gilligan's Island is recommended). This ensures that the code you write is your own, and that you only got general guidance from the other person. The University and the department take cheating very seriously.
{kind=link}