Project 2 - A Multithreaded Server
Out: Monday January 29th, 2001
Due: Wednesday February 7th, 2001
Assignment Goals
- To gain experience in writing and debugging multithreaded code.
In particular, you will be exposed to code that can deadlock or
have race conditions.
- To make use of common synchronization primitives such as
locks and condition variables.
- To gain some tangential exposure to network programming.
- To understand the concept of overlapping I/O and computation.
Background
As I'm sure you know, the Internet has exploded in popularity over the
past decade. Driving much of this explosion is the proliferation of
networked servers, which are programs that run "in the guts" of the
Internet. Client programs (such as web browsers) communicate with
these servers over the network, sending requests and reading back the
servers' responses. For example, a web browser will send a web server
a request for a particular web page; the server will process this
request, and then respond by sending back the page's HTML, which the
web browser reads, parses, and displays.
One of the challenges in building Internet services is dealing with
concurrency. In particular, many independent clients can
simultaneously send requests to a given server. A server therefore
must be designed to deal with concurrent requests. There are many
different strategies for doing this; we will explore two in this
project.
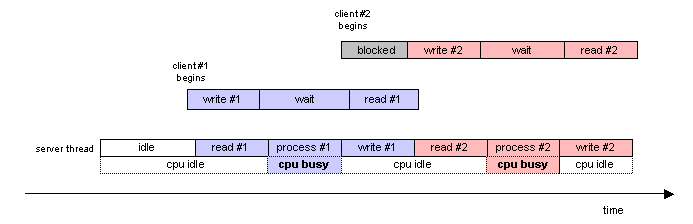
A very simple (too simple, in fact) design strategy is to build the
server as a single-threaded program. The server's single thread
waits until a new request arrives, reads the request, processes the
request, and then writes a response back to the originating client.
In the meantime, if another request arrives while the server is
processing the first, that other request is ignored until the first
has been dealt with fully:
A more sophisticated strategy would be to build the server as a
multithreaded program. When a task arrives at the server, a thread
is dispatched to handle it. If multiple tasks arrive concurrently,
then multiple server threads will execute concurrently. Each dispatched
thread does exactly what the single-threaded server did previously;
it reads the request, processes it, then writes a response:
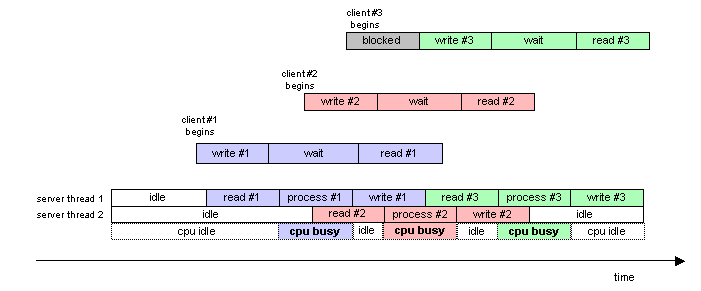
As the picture above shows, even though request #2 arrives while
request #1 is being processed by the first server thread, the second
server thread is available to deal with request #2 concurrently. As a
result, while the first server thread is processing request #1 (hence
using the CPU), the second server thread can read request #2 over the
network. Thus, network I/O and computation are overlapped. This has
many beneficial effects: the CPU is more effectively utilized, the
throughput of the server is increased, and the response time of the
server (as seen by the clients) is decreased.
In this assignment, you will be given the source code to a very, very
simple single-threaded networked server. Your goal is to convert
this single-threaded server into a multithreaded server, by building
a "thread pool" and integrating it into the server.
A thread pool is an object that contains a fixed number of threads and
supports two operations: dispatch, which causes one thread
from the pool to wake up and enter a specified function, and
destroy, which kills off all of the threads in the pool and
cleans up any memory associated with the pool.
The Assignment
Before you begin the assignment, log into spinlock or coredump, and
copy the following file into your directory:
/cse451kernels/gribble/server.tar.gz
This tar archive contains the source code to the single-threaded
server that you will modify, as well as some other files that we will
describe below. To extract the files from the archive, use
the following command:
tar -xvzf server.tar.gz
A directory called server/ will be created, and your
files will be extracted into it.
|
Part 1: Build a thread pool in C
|
Your first task is to design, implement, and test an abstraction
called a thread pool. Your thread pool implementation should
consist of two files: threadpool.h and threadpool.c.
In the server.tar.gz archive, we've provided you with
skeleton implementations of these files. You must not modify
threadpool.h in any way. To build your thread pool, you
should only add to the threadpool.c file that we've given
you.
As you should see from threadpool.h, your thread pool
implementation must support the following three operations:
threadpool create_threadpool(int num_threads_in_pool);
void dispatch(threadpool from_me, dispatch_fn dispatch_to_here, void *arg);
void destroy_threadpool(threadpool destroyme);
The create_threadpool() function should create and
return a threadpool. The threadpool must have exactly
num_threads_in_pool threads inside of it. If the threadpool
can't be created for some reason, this function should return
NULL.
The dispatch() function takes a threadpool as an
argument, as well as a function pointer and a (void *)
argument to pass into the function. If there are available threads in
the threadpool, dispatch( ) will cause exactly one thread in
the pool to wake up and invoke the supplied function with the supplied
argument. (Once the function call returns, the dispatched thread will
re-enter the thread pool.) If there are no available threads in the
pool, i.e. they have all been dispatched, then dispatch( ) must
block until one becomes available by returning from its previous
dispatch.
In either case, as soon as a thread has been dispatched, dispatch(
) must return.
The destroy_threadpool function will cause all of the
threads in the threadpool to commit suicide, after which any memory
allocated for the threadpool should be cleaned up. (I found this
to be the trickiest function to get right.)
You will be using the pthreads thread library to build your
multithreaded code. To learn about pthreads, type:
man -k pthread | less
This lists all of the routines present in the pthreads library (each
one has its own man page). Don't worry, there are many more routines
than you need to know about. In the server.tar.gz archive,
we've provided you with some example multithreaded code that uses
pthreads. All of the pthreads routines that you need to know about
are used in the example program, which is called
example_thread.c. To run the example, first type
make, then run the program example_thread.
In addition to this example code, we've also provided you with some
code (threadpool_test.c) that makes use of a thread pool.
Type the command make from inside the server/
directory to compile all the code in there, including your threadpool
source code and test code. An executable called
threadpool_test should be created. When you have a working
thread pool implementation, running the test code should result in
output that looks like this. Note
that just because you get this output while using your thread pool
implementation, it doesn't mean that your thread pool works. Your
implementation may have subtle race conditions that only show up
occasionally. We will be reading your source code to look for such
races.
Requirement #1: there should be NO BUSYWAITING in any of your
code.
Requirement #2: there should be NO DEADLOCKS and NO RACE
CONDITIONS in your code.
Hint #1: pthreads condition variables have the same operations
as semaphores (signal and wait), but unlike semaphores, condition
variables do not have history. If a thread calls signal, and there is
no other thread blocked on wait, then the signal will be lost.
Part 2: Use your thread pool to turn the single-threaded server
into a multithreaded server.
|
In the server.tar.gz archive, we have provided you
with a working implementation of a single-threaded network server.
The server source code is in the file called server.c. The
server implementation makes use of a network library that implements
all of the routines needed to read and write data over the Internet.
(We've provided you with the source code to this network library
in case you're curious. The source code is in the
SocketLibrary/ subdirectory.)
The server is designed to do the following:
- Create a "listening socket" on a network port
specified as a command-line argument to the server. Because
the server has created
a listening socket, clients can now open connections
to the server and send it data. In fact, multiple clients can
simultaneously open multiple connections to the server.
As explained in the background at the top of this web page,
the single-threaded server doesn't handle multiple connections
in parallel, but just works on them one at a time.
- Perpetually loop, doing the following:
- Accept a new connection from a client. (If there are
multiple connections that have arrived, only one will be
accepted. The rest will queue up inside the OS, and will be
accepted by the server in subsequent iterations through this loop.)
- Read data from the new connection. (Our server reads 10
bytes.)
- Process the request. Our server simply does some mindless
computation on the 10 bytes. (How much computation is does
can be altered by changing the NUM_LOOPS constant in the
server source code.)
- Write a response back to the client. (Our server writes
10 bytes.)
- Close the connection to the client.
What you must do is change the server to work in the following
way:
- Create a thread pool. (How big the pool is should be
specified as a command-line argument to your server.)
- Create a listening socket.
- Perpetually loop, doing the following:
- Accept a new connection from a client.
- Dispatch the connection to a thread from the thread
pool. (Yes, if the thread pool is empty, the server's
main thread will block in the dispatch until a thread
becomes available.)
The dispatch function should do the following:
- Read data from the dispatched connection.
- Process the request.
- Write a response back to the client.
- Close the connection to the client.
Thus, each time a new connection arrives at the server, the main
thread dispatches a thread from the threadpool to handle the
connection.
We've also provided you with an implementation of a network client.
You should not need to modify or understand the implementation of this
client. The client is single-threaded: it loops forever, and in each
loop iteration, it opens a connection to the server, writes a request,
reads a response, and closes the connection. Therefore, to fully test
your multithreaded server, you will need to run multiple clients in
parallel.
To launch the single-threaded server, give the following command (on
spinlock, coredump, or inside VMware):
./server 4324
Here, 4324 is the "port" that the server listens to. A port is kind
of like a phone number: a given workstation can have many servers
running on it, each listening to a different port. Because many of
your classmates might be running their server code on coredump or
spinlock, they might have already taken your port. Just try again
with a different port; you can choose any number between 1025 and
65535.
To launch a client, give the following command (in another window):
./client servername 4324
Here, servername is the IP address or hostname of the
workstation that the server is running on. For example, if you've run
the server on the machine coredump.cs.washington.edu, you'd specify
"coredump". The name localhost always refers to the
local machine. So, if you're running the client on the same
workstation as the server, you could launch a client like:
./client localhost 4324
To run multiple clients simultaneously, you could issue the following
commands:
bash$ ./client localhost 4324 &
bash$ ./client localhost 4324 &
bash$ ./client localhost 4324 &
etc..
To fully test your server out, you'll need to launch at least as
many clients as there are threads in your threadpool. (Think about
why.)
Requirement #1: You must implement your multithreaded server by
changing the source code to the single-threaded server
(server.c).
Requirement #2: You must not create or modify any other source files
(besides your threadpool implementation, of course).
Hint #1: You shouldn't need to change or add much code in
existing single-threaded server. We've nicely structured the
single-threaded server so that you can reuse most of its functions.
Hint #2: You shouldn't need to understand how network
programming works if you don't want to. By heeding hint #1, you
will be shielded from all of the details of network programming.
Don't be afraid to look under the covers, though!
Hint #3: The code we've provided doesn't ever print anything
out. While you're debugging your code, you might want to add some
print statements at various places in the client or server to
help you figure out what's happening. Make sure you disable the
print statements before doing part 3 of the assignment.
|
Part 3: Measure the performance of your multithreaded server
|
Now that you have a working multithreaded server, it's time to put
it through its paces. You will measure the throughput of your server
as a function of the number of threads in the threadpool, and the
amount of computation performed in the server. Throughput is simply
defined as the number of tasks per second that the server can handle.
This means that you need to instrument your server with code that
periodically displays the throughput that the server is handling.
To do this, just have the main thread (i.e. the code that calls
dispatch on the threadpool) increment a counter for every dispatch
it issues. Every now and then (i.e., whenever the counter increases
by some value, say 50 or 100), take a timestamp using the
gettimeofday() system call. Use these timestamps to
calculate and print out the server's throughput. (Don't worry about
keeping more than 2 timestamps around.)
To change how much computation the server performs, just alter the
value of the NUM_LOOPS constant in the server source code. Higher
numbers mean more computation. In fact, I suggest you make this
another command-line argument to your server.
What you need to do is measure the throughput of the server in the
following 36 conditions:
- # threads in pool = 1 and NUM_LOOPS=1, 100, 1000, 10000, 100000, 500000
- # threads in pool = 2 and NUM_LOOPS=1, 100, 1000, 10000, 100000, 500000
- # threads in pool = 4 and NUM_LOOPS=1, 100, 1000, 10000, 100000, 500000
- # threads in pool = 8 and NUM_LOOPS=1, 100, 1000, 10000, 100000, 500000
- # threads in pool = 16 and NUM_LOOPS=1, 100, 1000, 10000, 100000, 500000
- # threads in pool = 32 and NUM_LOOPS=1, 100, 1000, 10000, 100000, 500000
(You should run at least as many clients as you have threads in the
server's threadpool. For example, for # threads in pool = 4, you
should run at least 4 clients. )
To gather this data, run your clients and server inside VMware on a lab
workstation. This will guarantee that nobody else is running their
server on the same machine as you, thereby disturbing your experiment.
Using your favorite graphing package (such as Microsoft Excel),
plot a graph that looks something like:
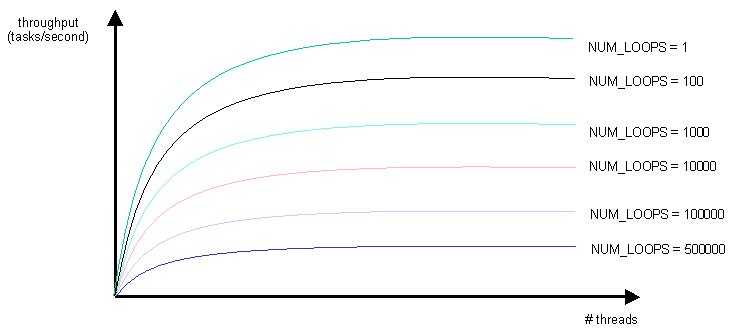 In other words, your graph should plot the throughput of your server
as a function of the number of threads in the thread pool. You should
plot a separate line for each different value of the NUM_LOOPS
variable. You should play with logarithmic-scale axis in order to get
your graph to reveal as much information as possible.
In other words, your graph should plot the throughput of your server
as a function of the number of threads in the thread pool. You should
plot a separate line for each different value of the NUM_LOOPS
variable. You should play with logarithmic-scale axis in order to get
your graph to reveal as much information as possible.
In hardcopy in class on Wednesday Feb 7th, you should hand in a
writeup of what you did, plus a printout of your modified
server.c and threadpool.c files.
Your writeup should include the following:
- A verbal description of the structure of your threadpool
implementation, including a list of any design decisions you
made.
- A list of critical sections inside your threadpool code (and
why they are critical sections).
- A description of the synchronization inside your threadpool.
What condition variables did you need, where, and why? Under
what conditions do threads block, and which thread is
responsible for waking up a blocked thread?
- The graph you produced in part 3, as well as an explanation
of why your graph is shaped the way it is. Try to explain
all of the interesting features on your graph, if possible.
You also need to electronically hand in your modified files
server.c and threadpool.c. To do this, follow these
steps:
- Make sure your modified files are in your account on spinlock
or coredump.
- cd into the directory that contains these files, and run the
following command:
tar -cvzf firstname_lastname.tar.gz threadpool.c
server.c
where firstname and lastname are your names.
So, I would run the following command:
tar -cvzf steve_gribble.tar.gz threadpool.c
server.c
This creates a new tar archive called firstname_lastname.tar.gz
- Copy firstname_lastname.tar.gz into the directory
called:
/cse451kernels/gribble/assignment_2/
This directory
has been set up so that you can write into it, but you can't
read or delete things from it. So, fear not, your classmates
won't be able to see anything that you put in there.
You need to submit your electronic version before the beginning of
class on Wednesday Feb 7th, i.e., no later than 9:30am on Wednesday
Feb 7th.