|
|
|

|
|
Project 4: Dynamic DNS
Out: Wednesday May 2
Due: Wednesday May 16 Friday May 18 (11:59 PM)
Turnin: Online
Teams: Approximately 2 people to a team
Shortcut to the DDNS protocol description page.
Shortcut to the DDNS implementation details page.
Assignment Overview
Tired of typing in all those IP addresses in Project 3?
In this project you'll implement a distributed name system modelled after the
Internet's Domain Name System (DNS). Instead of IP addresses, you'll be able
to use character string names to name your code running on a phone or a workstation.
The basic functionality of the system is to translate a character string name to an
IP address and port.
Our system is entirely separate from the Internet system. We're creating our
own name space
Because phones go offline a lot, our system supports dynamic registration of
IP address/port pairs. Thus its name: Dynamic DNS (DDNS). (DDNS exists
in the Internet as well, but isn't a well defined protocol, like ours is.)
A phone registers its current location (IP/port) when it comes online, and,
with any luck, registers that it is going away before it loses connectivity.
Three things make this project more challenging than the previous ones:
- In Project 3 you could try to interact with other groups' code.
In Project 4, you have to interact with other groups' code.
It's one distributed application (DDNS), just with lots of implementations.
- Project 4 isn't a simple client-server model. Instead, there is a
graph of DDNS servers and you may have to interact with many of them to
perform a single name to IP/port translation.
- Your Project 3 code has to work. Communication in Project 4 is
by RPC.
System Architecture
The overall architecture remains the same:
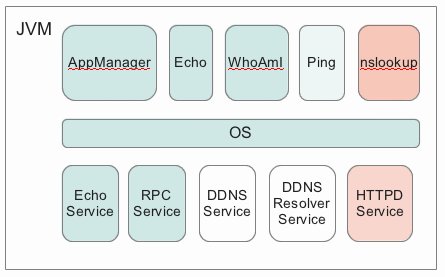
The major pieces are the DDNS Service
and DDNS Resolver Service. You're implementing them
from basically nothing. The global name of the DDNS Service, used
in RPC calls, is "ddns" The Resolver Service doesn't
export any method via RPC.
The HTTPD Service
is a web server that is (a) simple to implement, (b) very handy
for debugging, and (c) implemented in the code we provide (you just need
to weave it into your implementation). We also provide an
nslookup console application, which is handy for debugging.
On the Android side, you'll adapt your Ping application to work with
DDNS names - the user can provide a DDNS name rather than an IP/port.
The main goal is simply to make sure that all components of your system
will load and run on Android, using Ping as a test case. That verification
is important because Project 5 will be simply and Android app.
DDNS Namespace, Name Servers, and Resource Records
The DDNS namespace is what you're used to from names like www.cs.washington.edu:
hierarchical, dot separated fields, with the root to the right.
The name space is a tree, to the same extent that file system names are a tree.
Here's an example namespace, and its relationship to DDNS Service instances:
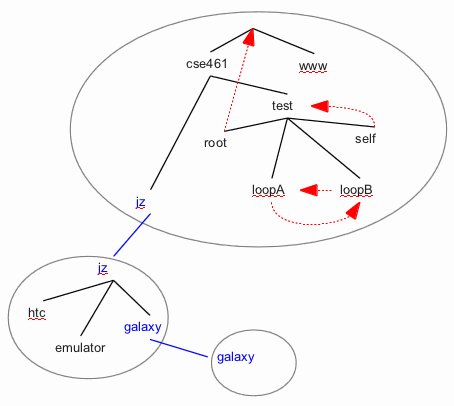 The black lines define the pure-tree part of the namespace. There is a root name at the top.
The root's name is the null string, so you don't see any text. Other names in the namespace
include cse461, jz.cse461, emulator.jz.cse461, and galaxy.jz.cse461.
The black lines define the pure-tree part of the namespace. There is a root name at the top.
The root's name is the null string, so you don't see any text. Other names in the namespace
include cse461, jz.cse461, emulator.jz.cse461, and galaxy.jz.cse461.
The ovals are DDNS Service instances, running on distinct systems. The namespace
is partitioned across the name server instances. The one containing the
root runs on machine cse461.cs.washington.edu. It's immediate child might run on some
always available system, say attu.cs.washington.edu. The one containing galaxy
might run on my phone, which is not always available.
Not every system instance has to be configured to run a name server.
My htc and emulator phones don't, in this example.
Associated with each name is a single resource record. There are four kinds of resource records
in DDNS:
- A - An address record holds an IP and port. For instance,
an address record for htc.jz.cse461 would hold the IP/port of the RPC service running on that device.
- SOA - A start of authority record is the root of the subtree of names located on a
single name server. There must be exactly one SOA record on a name server. In the figure, the root
would have an SOA record, as would the lower jz.cse461 and galaxy.jz.cse461 names.
SOA records contain the IP/port of the RPC service of the system they run on.
- NS - A name server record is a leaf node on its name server, linking to a corresponding
SOA record on some other server. The blue lines show those links. The entry closer to the root on each of
those links is an NS record. NS records contain the local RPC service's IP and port.
- CNAME - A canonical name record maps one name to another. These are shown
by the red links in the figure. For instance, the CNAME record for root.test.cse461
maps to the root, so names cse461.root.test.cse461 and cse461 are the same thing.
When a name server comes online (is connected to a network), it registers the IP/port of the local
RPC service with DDNS. This sets the IP/port of both the NS and the SOA records associated with it.
When it goes offline, it unregisters its address. That doesn't remove its name from the namespace,
just flags the name as having no current address.
Full Names
The root of the name space is the null string for a reason: convenience. Technically, it appears
as a suffix of every valid name. For convenience, the final dot of names can be ommitted when
the names are provided by users. Thus the name you type in a browser, say www.cs.washington.edu,
is really www.cs.washington.edu. as a fully qualified name.
Internally, DDNS allows only full names. It accepts shortened names in calls available to client code,
but immediately translates those names to full names for exchanging names with the various DDNS components.
Using only full names internally makes common operations, like comparing two names, simpler.
Full names also make your code simpler, because there is nothing special about the root - you don't have to
artificially inject it into the resolution process, or not, depending on whether or not the user has actually
typed it.
DDNS names are case sensitive. Real DNS names are not.
Name Resolution and Resolvers
Besides registering and unregistering addresses, the other operation supported by DDNS is name resolution,
which means looking up a name and returning the resource record associated with it.
Name resolution begins at the root, and proceeds component by component of the name, starting from the right.
For instance, to resolve htc.jz.cse461 we follow the cse461 edge out of the root, then the
jz edge. Because that node has an NS record, we proceed to the next name server, and evaluate
htc as a child of its SOA record.
If that procedure enounters a CNAME record, the portion of the name resolved so far is replaced by the
the alias contained in the CNAME record, and name resolution restarts at the root. For instance,
when resolution of jz.cse461.root.self.test.cse461 encounters the self CNAME record, the name is rewritten
to jz.cse461.root.test.cse461 and resolution starts over. This time it encounters the root
CNAME, rewrites the name to jz.cse461 and starts over. At this point, resolution can finish without
further rewrites.
Name resolution is carried out by name resolvers. Every system must be configured to have
a name resolution service component installed.
That component resolves names iteratively. It first asks the root name server to
resolve the name. If that name server encounters an NS record, it returns information about it to the resolver,
which is in charge of continuing the resolution process with the next name server.
Similarly, if the name server encounters a CNAME record, it returns that to the resolver, which rewrites the name
and restarts resolution.
If the name service finds that the name doesn't resolve to anything, it returns an error.
Following some simple rules will keep you from creating code that loops during resolution:
- Name servers never talk directly to each other.
- All invocations of name server methods is via RPC. There are no local (Java) calls to any of its methods (other than the ones made by the RPC service).
- Name resolution services don't expose any methods via RPC. They provide methods available to
local applications and services, but not methods available via RPC.
- Name servers never make local calls to name resolvers. Among other things, this means that
cached name records are never communicated to any remote machine.
- Applications never make calls to name servers. All such calls originate from name resolvers.
- Name resolution always begins at the root, and returns to the root if the name must be rewritten.
These rules ensure that the communication pattern has no loops: it's app to resolver to name server(s).
Trying aggressively to optimize by short-circuiting can lead to madness, via many difficult bugs.
Remember that the resolver can't assume there is a name server instance on the machine with it. This means
you can't just code Java procedure calls from the name resolver to the name server. In theory, you could do this in some
specialized cases, but it's easiest/best for the resolver to always talk to the name servers via RPC, no matter what.
It also means your code must work even when there is no name server loaded on some particular device.
Dealing with Naming Loops
You may be wondering if it's guaranteed that the resolution procedure just described eventually terminates.
The answer is no. The example namespace contains a simple loop:
loopA.test.cse461 evaluates to loopB.test.cse461 and vice versa.
While you could think about preventing such loops, it's hopeless:
the loops could span any number of name servers.
This means your code must deal with the possibility of loops.
We deal with possible loops using two similar mechanisms, both based on limiting the number
of resolution steps we're willing to take.
To avoid loops that span multiple zones, the resolver puts a limit on the number of resolve()
RPCs it makes to name resolvers.
To avoid loops formed within a zone, the name service puts a limit on how many edges it will traverse
before giving up. (A conformant name service could skip this check, since the zone is finite. However,
using it provides added insurance that your code doesn't go into an infinite loop, especially if you
try to optimize CNAME handling.)
These limits mean that it's conceivable that some valid names can't be resolved.
The limits need to be large enough that that's very unlikely. On the other hand, large limits are
a performance issue when a loop actually exists.
Caching: Positive and Negative
As you can imagine, this process can be pretty slow. To help speed things up, name resolution service components
maintain a cache of recently fetched resource records. The cache is simply a map from a name to a resource
record. Records received from name servers are placed in it. Because the cache can go out of date, each cache
item is removed from the cache after some timeout interval (of your choosing). This means that the resolver may
give incorrect results, because the data associated with a name may change in the name servers while an item is cached.
The item will eventually time out, though.
Going over the network is so expensive (in time and energy) that we want to make use of any information we get that way.
Some of the information we get is negative. For instance, after resolving name foo.cse461 we learn
that name doesn't exist. The resolver records that information in the local cache, so that if the name is used again
in the near future we don't have spend even more energy finding out it doesn't exist.
A similar but distinct situation is that some name name exists but there is currently
no address associated with it. (htc.jz.cse461 exists, but is offline, say.) We cache that as well.
The resolver distinguishes the two cases because it might be important to some of the resolver's clients,
which are "any application anyone wants to write, ever."
Registration Keep-Alive
Ideally, a system that registers an address for some DDNS name will unregister the address when
that system goes offline. In practice, DDNS can't rely on that happening, since the system can
simply lose network connectivity without warning.
Because we don't want to advertise a no longer working address for a name indefiniely,
DDNS requires that a system registering an address repeat the registration periodically.
If the registration is not repeated within a DDNS name server specified period, the name
is unregistered by the DDNS name service.
In terms of implementation, each successful register() call on DDNS returns a "lifetime"
value indicating how many seconds the registration will be maintained before it is automatically
unregistered. The name should be re-registered before that time expires.
Security
DDNS has a security feature: each node in the distributed name tree has a password associated with it,
and updates to its resource record require the password. No password is required to read the record, so
anyone can resolve any name. Only the "owner" of the record knows the password, presumably, and so alone
is able to set the IP/port information, say.
We imagine, but don't implement, that all communication between name resolvers and and name servers is
over encrypted connections. Our imagination addresses just one of the many, many security issues with
name servers, but it's better than what we actually do: send passwords in cleartext.
Our "security mechanism" actually has a single, pragmatic motivation. Without something like passwords,
any name resolver can trash the name space because of an unintended bug. With passwords, your buggy
name resolver can trash only those names you have the password for, which you own. Thus, passwords
provide some failure isolation, which should help everyone debug their code.
The HTTPD Service
The HTTPD service provides web browser access to running services. I use it to dump
the current DDNS name server tree, and the resolver cache contents. (It's hard to
know which component is the problem when your resolve a name and don't get the answer
you expect. Examining the component states helps.) You can use it for that,
or anything else you like - the code is small, and simple.
At the highest level, you include a small web server implementation in your project,
nanoHTTPD. (I've made one small
modification to the source, so provide a copy with other project files.)
Neither browsers nor nano speak our RPC, of course, so nano opens
a TCP server socket and waits for HTTP requests on it. When it gets one, it invokes
its own server() method. The code we provide subclasses nano, overriding
the server() method. Our code assumes that the first component of the URI
is a service name. It locates the service (by (HTTPProvider)OS.getService(servicename),
then tries to invoke method httpServe(String[] uri) on it. The argument is a parsed
version of the URI.
For example, if the web server on a system running name server with SOA jz.cse461
creates port 192.168.0.77:36128, typing in the browser the URL http://192.168.0.77:36128/ddns
will invoke the httpServer() method of service ddns. My full implementation
is:
@Override
public String httpServe(String[] uriArray) { return toString();}
What you see in the browser is a dump of the name server's resource records, because that's what my toString()
produces.
My implementation of httpServer for the name resolver does a bit more. URL
http://192.168.0.77:36128/ddnsresolver/cse461.root.test.cse461 causes the resolver
to resolve the second component of the URI, cse461.root.test.cse461, to display what
result it got, and then to dump the full cache it maintains.
You can implement whatever you want in your httpServe() methods.
Here's what the browser diplays for http://192.168.0.77:46131/ddns (for me).
This is the root name server, when the jz.cse461 name server is running.
Zone:
'' [Type: SOA IP: 192.168.0.77 Port: 46130]
'cse461.' [No current address]
'jz.cse461.' [Type: NS IP: 192.168.0.77 Port: 60917]
'odin.cse461.' [No current address]
'test.cse461.' [No current address]
'loopA.test.cse461.' [Type: CNAME Alias: loopB.test.cse461.]
'loopB.test.cse461.' [Type: CNAME Alias: loopA.test.cse461.]
'normal.test.cse461.' [No current address]
'root.test.cse461.' [Type: CNAME Alias: ]
'self.test.cse461.' [Type: CNAME Alias: test.cse461.]
'www.' [Type: A IP: 192.168.0.77 Port: 46131]
'cse461.www.' [No current address]
'jz.cse461.www.' [Type: A IP: 192.168.0.77 Port: 36128]
'odin.cse461.www.' [No current address]
To make it easy for you to browse remote servers, including those
implemented by other people, DDNS follows a convention of registering
the name servers under cse461.www. This part of the name space
is maintained by the root server, which has a well known location.
In the example above, the jz.cse461 HTTP server has indicated
that it's at 192.168.0.77:36128, by having registered that address
as name jz.cse461.www.
The 22.5/7 Availability Root Server
There is an almost-always-up root server running at cse461.cs.washington.edu:46130.
That information is "well-known," and needs to be provided statically to each name server
instance. (The name server can't look up the address of the root using DDNS, because it
can't ask the root to resolve a name without having the address of the root.)
While testing, you can run your own root, of course.
That server runs an HTTPD service on port 46131.
That service implements the scheme described above:
.../ddns dumps the name server's tree; .../ddnsresolver dumps
the resolver's cache; .../ddnsresolver/foo.bar causes the resolver to
try to resolve name foo.bar, to display the result of doing that, and to
dump its cache. (Again, you can implement whatever you want for your server. Until
you've tried this, though, it's hard to appreciate how useful it is, so I really
recommend the few minutes work it is to add it to your project.)
DDNS Protocol Overview
For your convenience, the protocol description is located on another page.
Implementation Details
Also neatly kept out of the way on another page.
Suggested Extension
Make more aggressive use of the resolver cache to avoid querying the root server so often.
What to Turn In
- A short report telling us the names of the members of your group, the xxxx.cse461 zone
name you've allocated, and anything about your setup that you think we might not expect, realizing
that we're going to try to build and run your code. What we expect is that we need to bring up
Eclipse, point it at your workspace, and then launch the AppManager. It's not clear that
Eclipse will know what config file we should use, though, so that would be the sort of thing you
should tell us.
If you've changed the scheme for interacting with your code from browser from the one described above
(and implemented in the code we're distributing), you should tell us that as well.
If your DDNS implementation doesn't work, also include a description of what isn't working.
If you've implemented extensions, describe those.
Finally, if you have general comments on the overall DDNS architecture we imposed
(what worked well for you, what things you think are weaknesses of the design),
talk about those.
- A .tar.gz of your entire Eclipse workspace, after having first done a clean.
Updates: 5/14 8:49PM
These updates will help us grade your projects.
- To help us evaluate your resolver component, please resolve a small set of names and include the results
in your report. The names to evaluate depend on the DDNS name allocated to your group.
The specific names below assume that name is foo.cse461,
but you should adjust them to match your actual name. (For example, I'd substitute
"jz" for "foo", since the DDNS name allocated to me is jz.cse461.)
- foo.submit.test.cse461
- w.foo.submit.test.cse461
- x.foo.submit.test.cse461
- y.foo.submit.test.cse461
- z.foo.submit.test.cse461
The results will vary from group to group.
- To help us evaluate your name service component, we'd like you to create two specific names in your group's
main zone, and then to start an instance of your name server for that zone and leave it running.
- Create name a.foo.cse461 (subtituting for foo as above). This should be an A record.
You should register for it the IP and port that are registered for foo.cse461. For instance, if
jz.cse461 resolves to 128.208.2.207:35329, then so would a.jz.cse461.
- Create name b.foo.cse461 (again, with subtitution for foo). This should be a CNAME
record whose alias is "." (the root of the DDNS name service).
- Start an instance of your name service implementation, managing your main zone including the two new
names, on attu4.cs.washington.edu and leave it running when you log out. We'll try to contact
it to resolve a.foo.cse461 and b.foo.cse461.
The trick here is to leave it running when you log out. Any way you can achieve that is fine. Here
are some instructions I've tested. They require that you can launch an instance of your name server
from the terminal. (It may work to launch Eclipse following these instructions, and then use it
to launch an execution, but I haven't tested that.) The '$' represents the command line prompt on attu4.
C-a is control-a.
- $ screen <command to run you server>
- $ C-a d
That detaches your from the screen. A screen number will be printed, something like
7826.pts-57.attu4. Make a record of it.
- Now log out.
- Once we've contacted your running instance, we'll send you mail and you can terminate it.
To do that, login to attu4, issue the command screen -r 7826.pts-57.attu4. That will
reconnect you to your server. Kill its execution, then C-a k to kill the instance of screen.
Notes
- The DDNS specification is precise about what information goes on the wire. It's fuzzy about what
the receiver of that information should do with it -- we know that calling resolve() should
result in name resolution, but we don't specify all details of how that works, or what to do in every case.
You should keep clear that there are implementation choices, and you're free to make whatever decisions about
them you want, so long as you interact with other DDNS implementations in sensible ways.
Among the choices you can make are just what your provide in the resolver API available to local appplications.
Our application, nslookup, requires just two things: that there be a resolve(String name)
method that returns a DDNSRRecord object, and that DDNSRRecord implements a useful toString().
You don't have to conform to even that, though - it's easy to modify nslookup to whatever interface
you choose.
- As one example of the distinction between what you implement and what how the intended functionality is described,
consider the internal data structure used by the name server component.
Pictures of name spaces always show trees where the nodes are labelled one name component, not the full
name the node represents. Your implementation can work similiarly, or it can store full names at the nodes.
I found it handy to store full names at each node.
|
