|
|
|

|
|
Homework #1
out: Monday April 2nd, 2012
due: Thursday April 12th, 2012 by 6:00pm.
[
summary |
part a |
interlude |
part b |
how to submit |
grading ]
Homework #1 has two parts. In part A, you will finish our
implementation of a C data structure: a doubly-linked list. In part
B, you will use the linked list, and also an AVL tree implementation
that we give you, to implement a simple image processing
application. Please read through this entire document before
beginning the assignment, and please start early! This assignment
involves messy pointer manipulation and malloc/free puzzles, and
these can cause arbitrarily awful bugs that take time and patience
to find and fix.
Context.
If you've programmed in Java, you're used to having a fairly rich
library of elemental data structures upon which you can build, such
as vectors and hash tables. In C, you don't have that luxury: the C
standard library provides you with very little. In this assignment,
you will add missing pieces of code in our implementation of a
generic doubly-linked list.
At a high-level, a doubly-linked list is incredibly simple; it looks
like this:

Each node in a doubly-linked list has three fields; a payload, a
pointer to the previous element in the list (or NULL if there is no
previous element), and a pointer to the next element in the list.
If the list is empty, there are no nodes. If the list has a single
element, both of its next and previous pointers are NULL.
So, what makes implementing this in C tricky? Quite a few things:
- First, we want to make the list useful for storing arbitrary
kinds of payloads. In practice, this means the payload element in
a list node needs to be a pointer supplied by the customer of the
list implementation. Given that the pointer might point to
something malloc'ed by the customer, this means we might need to
help the customer free the payload when the list is destroyed.
- Second, we want to hide details about the implementation of
the list by exposing a high-level, nicely abstracted API. In
particular, we don't want our customers to fiddle with next and
previous pointers in order to navigate through the list, and we
don't want our customers to have to stitch up pointers in order to
add or remove elements from the list. Instead, we'll offer our
customers nice functions for adding and removing elements, and
we'll offer our customers a Java-like iterator abstraction for
navigating through the list.
- Third, C is not a garbage-collected language: you're
responsible for managing memory allocation and deallocation
yourself. This means we need to be malloc'ing structures when we
add nodes to a list, and we need to be free'ing structures when we
remove nodes from a list. We also might need to malloc and free
structures that represent the overall list itself.
Given all of these complications, our actual linked list data
structure ends up looking like this:
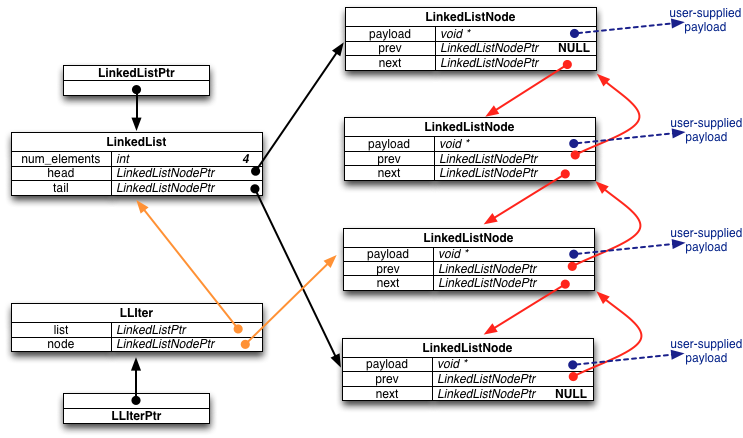
Specifically, we defined the following types and structures:
- LinkedListPtr: a pointer to a LinkedList
structure. When our customer asks us to allocate a new, empty
linked list, we malloc and initialize a LinkedList
structure, and return a pointer to that malloc'ed structure to
the customer.
- LinkedList: this structure contains bookkeeping
information about an entire linked list, including the number of
nodes in the list, and pointers to the head and tail nodes of the
list.
- LinkedListNodePtr: a pointer to a LinkedListNode
structure.
- LinkedListNode: this structure represents a node in a
doubly linked list. It contains a field for stashing away
(a pointer to) the customer-supplied payload, and fields pointing
to the previous and next LinkedListNode in the list. When a
customer requests that we add an element to the linked list, we
malloc a new LinkedListNode to store that element, then we do
surgery to splice the LinkedListNode into the data structure and
we update the LinkedList record as well.
- LLIterRecordPtr: sometimes customers want to navigate
through a linked list. To help them do that, we provide them with
an iterator. LLIterRecordPtr points to a structure that keeps the
state of an iterator. When a customer asks for a new iterator, we
malloc a LLIterRecord, and return a pointer to it to the customer.
- LLIterRecord: this structure contains bookkeeping
associated with an iterator. In particular, it tracks the list
that the iterator is associated with and the node in the list that
the iterator currently points to. Note that there is a consistency
problem here: if a customer updates a linked list by removing a
node, it's possible that some existing iterator becomes
inconsistent by pointing to the deleted node. So, we make our
customers promise that they will free any live iterators before
mutating the linked list. (Since we are generous, we do allow
a customer to keep an iterator if the mutation was done using
that iterator.)
What to do.
You should follow these steps to do Part A of this assignment:
- Make sure you are comfortable with C pointers, structures,
malloc, and free. We will cover them in detail in lectures, but
you might need to brush up and practice a bit on your own; you
should have no problem searching the web for practice programming
exercises on the Web for each of these topics.
- Pick a CSE Linux machine to use to do your assignment. You
have your choice of using a CSE virtual machine, one of the
Linux-based workstations in the undergraduate labs, or ssh'ing into
attu.cs.
- On that machine, download the following tar ball:
hw1.tar.gz
and extract out the hw1/ directory using the Linux
command tar -xvzf hw1.tar.gz
- Look inside the tarball. You'll see a number of files and
subdirectories; the ones that are relevant to part A are:
- Makefile: a makefile you can use to compile the
assignment using the Linux command make all.
- LinkedList.h: a header file that defines and documents the
API to the linked list. A customer of the linked list includes
this header file and uses the functions defined within in.
Read through this header file very carefully to understand
how the linked list and iterator is expected to behave.
- LinkedList_priv.h, LinkedList.c: LinkedList_priv.h is a
private header file included by LinkedList.c; it defines the
structures we diagrammed above. LinkedList.c contains the
partially completed implemented of our doubly-linked list. Your
task will be to finish the implementation. Take a minute and
read through both files; note that there are a bunch of places in
LinkedList.c that say "STEP X:" these labels identify the missing
pieces of the implementation that you will finish.
- test_linkedlist.c: this file contains unit tests that we
wrote to verify that the linked list implementation works
correctly. The unit tests are written to use the
googletest unit testing framework. As well, this test driver
assists the TA in grading your assignment: as you add more pieces
to the implementation, the test driver will make it further
through the unit tests, and it will print out a cumulative score
along the way. You don't need to understand what's in the test
driver for this assignment, though if you peek inside it, you
might get hints for what kinds of things you should be doing in
your implementation!
- example_program_ll.c: this is a simple example of how a
customer might use the linked list; in it, you can see the
customer allocating a linked list, adding elements to it,
creating an iterator, using the iterator to navigate a bit, and
then cleaning up.
- gtest: this directory contains header files and a library
for googletest. You don't need to understand anything in this
directory for this assignment.
- solution_binaries: in this directory, you'll find some Linux
executables, including test_suite and example_program_ll. These
binaries were compiled with a complete, working version of
LinkedList.c; you can run them to explore what should be
displayed when your Part A of the assignment assignment is
working!
- Run "make" to verify that you can build your own versions
of example_program_ll and test_suite. Make should print out a
few things and you should end up with two new binaries inside
the hw1 directory.
- Since you haven't yet finished the implementation of LinkedList.c,
the binaries you just compiled won't work correctly yet. Try
running them and note that example_program_ll produces a
segmentation fault (indicating memory corruption or a pointer
problem), and test_suite prints out some test suite information
before crashing out.
- This is the hard step: finish the implementation of LinkedList.c.
Go through it, find each comment that says "STEP X", and replace
that comment with working code. The initial steps are meant to
be relatively straightforward, and some of the later steps are
trickier. You will probably find it helpful to read through
the code from top to bottom to figure out what's going on.
You will also probably find it helpful to recompile frequently
to see what compilation errors you've introduced and need to fix.
When compilation works again, try running the test driver to
see if you're closer to being finished.
- We'll also be testing whether your program has any memory
leaks. We'll be using Valgrind
to do this. To try out Valgrind for yourself, do this:
- cd into the solution_binaries subdirectory, and run
the following command:
valgrind --leak-check=full ./example_program_ll
Note that Valgrind prints out that no memory leaks were found.
Similarly, try running the test driver under Valgrind:
valgrind --leak-check=full ./test_suite
and note that Valgrind again indicates that no memory leaks were
found.
- now, cd back up into the hw1 directory, compile your
versions of the example_program_ll and test_suite binaries
and try running them under Valgrind. If you have no memory leaks
and the test_suite runs to completion, you're done with part A!
A linked list is a powerful building block, but it has limitations.
One is that it takes O(N) operations to find an element within a
linked list; as a result, it is not an appropriate tool for solving
problems involving looking up a piece of data within a large data
set. As well, a linked list makes no effort to keep its elements
sorted in any particular order; as a result, it is not an
appropriate tool for sorting data or accessing items of a set in
order.
An AVL tree is a
data structure that can solve both kinds of problem. An AVL tree is
a self-balancing binary search tree: the heights of both of the two
child subtrees of any node differ by at most once. Because of this,
lookup, insertion, and deletion all take at most O(log N) time in
both the average and worst cases, making it an efficient data
structure for lookup operations. As well, since it is a binary
tree, an in-order
traversal of the tree visits stored elements in ascending order,
making it an appropriate data structure for sorting items or
accessing items in sorted order.
Instead of having you finish implement an AVL tree, we have provided
you with a finished implementation. Our implementation supports
tree creation, node insertion, node lookup, node deletion, and tree
deletion. As well, we have provided you with an iterator that
allows you to access items in order, in reverse order, or in the
order defined by a pre-order
traversal.
Our implementation follows the same general structure as the
LinkedList implementation. The following files are relevant:
- AVLTree.h: defines the public interface to an AVL
tree. Similar to part A, we hide the implementation details and
data structure fields from customers.
- AVLTree_priv.h: a private header file included by
AVLTree.c that defines the internal data structures and fields of
an AVL tree.
- AVLTree.c: the code that implements the AVL tree.
- test_avltree.c: a unit test driver for our AVL tree
code.
- example_program_avltree.c: this file is a simple
example of how a customer might use the AVLTree implementation.
What do do.
You should follow these steps to do the interlude of this assignment:
- Read through AVLTree.h carefully in order to
understand the interface and operations available to you.
You should find plenty of similarites to the linked list module.
- Scan through the Wikipedia pages on binary search
trees, on AVL
trees, and on tree
traversal to remind yourself about trees and their properties.
Read through the example_program_avltree.c source code and
make sure you understand how to use the AVL tree as a key/value
store, in particular how you pack a key and value into a
structure, store that structure in the tree, and update the value
of an element within a tree.
Context: color intensity histograms
In the abstract, an image is represented by a height, a width, and
an array of (height x width) pixels. A pixel is a (red, green,
blue) triple, where each component is typically an 8-bit number.
As well, we can calculate the luminosity of each pixel,
which is a measure of how bright the human eye perceives the pixel
to be. Luminosity is defined by the following function of the red,
green, and blue values:
L(R,G,B) = (0.3 x R) + (0.59 x G) + (0.11 x B)
In this part of the assignment, you will use your linked list
implementation and our AVL tree to build a simple image processing
utility that calculates and renders an image color intensity
histogram. (Throughout this writeup, we'll use imagehist as
shorthand for "image color intensity histogram."). In a nutshell,
an imagehist calculates number of pixels that have a particular red,
green, blue, or luminosity value; rendering an imagehist means
drawing four histograms. The first is a red intensity histogram,
which plots, for each possible red intensity value 0-255, the number
of pixels that have that red intensity value. The second, third,
and fourth histograms are similar to the red, but for green, blue,
and luminosity.
Let's break this down. Let's imagine you have the following
image (it's a small image, but we're showing it with very large
pixels):

The image has width 4 and height 3. The 12 pixels within the image
have the following (R,G,B,L) values, starting at the top-left, and scanning
each row left to right:
(255, 0, 0, 77) (255, 0, 0, 77) (255, 128, 0, 152) (255, 128, 0, 152)
(128, 128, 0, 114) (128, 128, 0, 114) (0, 255, 0, 150) (0, 255, 0, 150)
(0, 128, 255, 104) (0, 128, 255, 104) (0, 0, 255, 28) (0, 0, 255, 28)
So, if we consider each of R, G, B, L independently, we see that
those colors have the following intensity counts:
R:
- 0: 6 pixels
- 128: 2 pixels
- 255: 4 pixels
|
|
G:
- 0: 4 pixels
- 128: 6 pixels
- 255: 2 pixels
|
|
B:
- 0: 8 pixels
- 128: 0 pixels
- 255: 4 pixels
|
|
L:
- 28: 2 pixels
- 77: 2 pixels
- 104: 2 pixels
- 114: 2 pixels
- 150: 2 pixels
- 152: 2 pixels
|
Plotting these as histograms, we end up with:

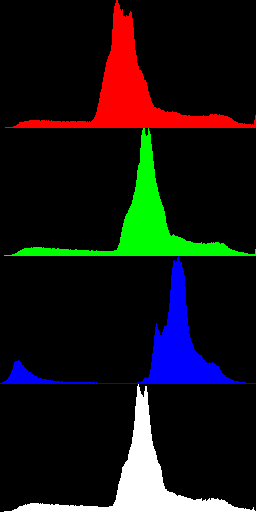
For a more complex image, the histograms have a more noticable
shape. For example, here's a photograph of a mountain and the
corresponding histograms; here, we've omitted the axis, labels, and
so on from the graphs and just plotted the data itself.
Context: PPM formatted images
The next piece of context that you need for part B is to understand
the PPM ("portable pixel map") image format, since you will be
writing a program that parses a PPM image and generates a imagehist
in PPM format from it. The PPM format is extremely simple; you can
run "man ppm" on a Linux machine to read up on it. A PPM
file contains the following:
P6\n
[width] [height]\n
[depth]\n
[pixel][pixel][pixel]...etc.
So, the file's first line has the ASCII character 'P', the
ASCII character '6', and the newline character. The file's second
line contains the width (as an ASCII-encoded integer), a space
character, the height (as an ASCII-encoded integer), and a newline.
The file's third line contains a single ASCII-encoded integer
representing the maximum intensity a pixel color can have: for this
assignment, you should assume that this depth number is 255,
followed by a newline.
After this header, the image contains an array of pixel data. Each
pixel is represented by three bytes: one byte containing a number
for the red intensity, one byte containing a number for the green
intensity, and one byte containing a number for the blue intensity.
There are no spaces or other characters separating the pixels; it is
just an array of (width x height x 3) bytes of data. PPM images
do not contain luminosity information directly; you will need to
calculate luminosity given the R,G,B values that you read.
That's it! Given an image in some other format, it is easy to
generate PPM data for the image: you just use the NetPBM tools
installed on your Linux distribution. For example, given a JPEG
file named "my_image.jpeg" you can convert it to PPM using
the following command ("PNM" is a superset of PPM, which
is why you'll see that acronym in a few of the tools we use):
jpegtopnm my_image.jpg > my_image.ppm
Summary of Part B
Your task in Part B is to write a program called "image_hist" that
reads in a PPM-formated image from standard input, parses it to
extract out pixel data into a linked list of pixels, uses a AVL
trees to calculate R, G, B, and L intensity histograms, and then
uses those histograms to generate a PPM-formated histogram image
similar to the one next to the mountain image above.
What to do.
You should follow these steps to do this assignment:
- Look at the file "image_hist.c" -- notice that there
is essentially no code in it. Your job is to design a program that
solves Part B, break the program down into a set of functions that
are building blocks, and then implement those inside the
image_hist.c file.
- Look inside the images subdirectory. There are four base jpeg
images in that directory, as well as four histogram images that
were generated from the base images. Open them all up (use
firefox) to see what kind of output you are expected to generate.
- Look inside the solution_binaries subdirectory, and notice that
we've given you a working image_hist binary. Try using the binary
to see if you can regenerate histograms from the example base
images we've provided. For example, to generate the histogram from
the images/idaho.jpg image, run this command:
jpegtopnm images/idaho.jpg | solution_binaries/image_hist | ppmtojpeg > images/new_idaho.jpg
- Design and implement your program. I suggest you break it
down into the following steps:
- Design some structs that hold Pixel data (i.e., r,g,b,l
intensities) and histogram records (i.e., an intensity and a
count).
- Write code to read PPM data from stdin and parse it into
a series of Pixel structs.
- Write code to append the series of Pixel structs to a linked
list. (It is possible to implement this program without storing
pixel values in a linked list, but we'd like you to do this to
get practice using your linked list implementation.)
- Write code that iterates over the linked list, generating
four histogram data structures, one for the red component
intensity of the pixels, one for green, one for blue, and one for
luminosity. A histogram is a map from key (color intensity) to
count (number of pixels that have that intensity). You an use an
AVL tree to store the map. To do this, you'll need to store a
histogram structures in the AVL tree; so, you'll need to write a
comparator function that looks at the intensity field of the
histogram structure, and you'll need to insert/lookup/update the
tree as you iterate over the pixels.
- Write code that allocates a region of memory to store your
generate histogram image, and iterate over your AVL trees to
generate the image data.
- Write code that writes out the histogram image, in PPM
format, to stdout.
- Be sure that you're cleaning up all memory, i.e., be sure
your code has no memory leaks.
- Use valgrind to make sure that your code has no memory
errors or leaks.
- Test your program against our example base images, making
sure that the histogram image you emit looks the same as the
examples we provided. You don't have to match it identically,
but try to get it as close in dimension and style as you can.
When you're ready to turn in your assignment, do the following:
- In the hw1 directory, run "make clean" to clean out
any object files and emacs detritus; what should be left are your
source files.
- Create a TURNIN.TXT file in hw1 that contains your name,
student number, and UW email address.
- cd up a directory so that hw1 is a subdirectory of your
working directory, and run the following command to create your
submission tarball, but replacing "UWEMAIL" with your uw.edu
email account name.
tar -cvzf hw1_submission_UWEMAIL.tar.gz hw1
For example, since my uw.edu email account is "gribble", I would run the command:
tar -cvzf hw1_submission_gribble.tar.gz hw1
- Use the course dropbox (there is a link on the course
homepage) to submit that tarball.
- Fill out the following survey to give us feedback on the
assignment:
https://catalyst.uw.edu/webq/survey/gribble/163454
We will be basing your grade on several elements:
- The degree to which your code passes the unit tests contained
in test_linkedlist.c. If your code fails a test, we won't attempt
to understand why: we're planning on just including the number of
points that the test drivers print out.
- We have some additional unit tests that test a few additional
cases that aren't in the supplied test driver. We'll be checking
to see if your code passes these as well.
- The quality of your code. We'll be judging this on several
qualitative aspects, including whether you've sufficiently
factored your code and whether there is any redundancy in your code
that could be eliminated.
- The readability of your code. For this assignment, we don't
have formal coding style guidelines that you must follow; instead,
attempt to mimic the style of code that we've provided you.
Aspects you should mimic are conventions you see for
capitalization and naming of variables, functions, and arguments,
the use of comments to document aspects of the code, and how code
is indented.
|

 CSE Home
CSE Home