Recognition
First, I computed eigenfaces as a basis for my work. I implemented the speedup as described in the project. It took little time to implement and probably saved me at least an hour of debug time. Here's the average face and a few eigenfaces.
 |
 |
 |
 |
 |
 |
I tried to identify all of the smiling faces based on my eigendecomposition of the neutral faces using different numbers of eigenvectors. Here is a plot of the number of eigenvectors used against the number of successful matches, out of a possible 33.
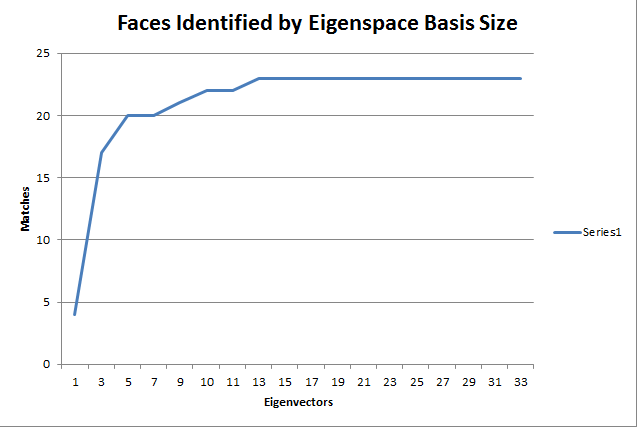
The missed matches were all quite reasonable, and their subjects were usually smiling with enough zest to make the images look completely dissimilar. Here is one such example. While the neutral face is female and the smiling face is male, the wink is pretty different from the eigenbasis and the facial shape is close.


Because I had already implemented the speedup, I tested my recognition with higher-resolution eigenfaces to see if that made any difference. I still couldn't break the 23/33 barrier though. Here's the full-resolution average and a couple faces.



Q1
Using more eigenvectors is advantageous, but only to a point. After 13 eigenvectors, my program had already matched 23 faces. Going all the way to 33 yield no additional matches. However, since the Jacobian operator is calculating all of the eigenvectors anyway, and it is the clear bottleneck, there isn't a huge cost to use more eigenvectors than necessary. On larger data sets this would be a more crucial decision, and if I hadn't implemented the optimization I would have wanted to recompute my eigenfaces as seldom as possible, so I would have leaned towards using too many rather than too few.
Q2
I was not able to match more than 23 faces, even using full-resolution eigenfaces. The mis-matches, though, were all reasonable. Not all were as extreme as the one shown above, but they were all close on skin tone and facial features. Here are a couple other mis-matches. The left pair's neutral image is blurry and washed out. Due to lighting and cropping, I think the match my program chose for the right pair looks closer than the actual match.





Cropping and finding
The first picture I worked on cropping was the elf. I had a lot of trouble getting my eigenfaces to find the baby, probably because many of the input images have beards and glasses. The baby's face also has very little variance, which made it hard to isolate from the walls. I ended up converting the image to grayscale before doing any projection. I also used the distance from the mean to center the window rather than the MSE, which ended up being halfway off of the face because of the variance term in my MSE calculation. I had similar problems cropping my own image, and the severe red-eye definitely didn't help. Once I converted to grayscale I had much more success, with the only challenge being the variance term again.




For the group portion, I used the test photo and one of the big class photos. The three-person photo came out pretty well, although the faces weren't exactly flush. This is because when the window overlaps the face's edge it dramatically boosts the variance. I'm preferring windows with high variance to avoid picking up walls, and this shows with the three-person photo. The class photo is absolutely chaotic, and only a select few faces were found.


Q1
I used the recommended values of .45, .55, and .01 for the elf photo. For my photo, I used .35, .5, and .01. For the three-person group photo, I used .25, .4, and .01 For the full class photo, I used .35, .55, and .02
Q2
I found many false negatives, most noticeably in the group photo. The root of most of these problems is that areas with low texture can project easily to face-space, since if all coefficients are 0 the projected face is simply blank. To counteract this, I divided each image's error by its variance, increasing the error for low-variance images. This, however, prefers edges. To counteract this, I multiplied by the distance to the face mean to avoid areas with huge variance but no facial resemblance. These artifacts still remain though, and I found had to tune these values somewhat for each image.
Verification
For the verification portion, I wrote a batch script to test verifyFace at a large range of thresholds and plot the numbers of true and false positive and negative results. My experiment wasn't perfect, because I always tested against the next face for negative results, for instance verifying smiling-5.tga against neutral-4.tga rather than randomly selecting for my negative tests. Here is a graph of my results. Thresholds are given in billions.

Q1
I first ran a verification with a random threshold, and saw that the MSE was around 1.2 trillion. So I tested from 5 billion to 14 trillion, the point at which there were no more positives. This allowed me to capture the full range of useful thresholds, as at 5 billion there are minimal true positives (4/33), and at 14 trillion there are no true negatives.
Q2
I would say the best rate is at 1 trillion, where the false positive and false negative rate are both 5/33, or 15 percent.




















