|
|
|
 |
|
Homework 3: RFID Networks / Design
Out: Monday October 15
Due: Constantly, until Wednesday October 24, 11:59PM
Please print a copy of each report page as you
modify it, for backup. Do not turn these pages in.
Version History
- V2.0 - 10/15/2007
Original distribution.
Overview
The goal of this assignment is to design an inventorying algorithm for an
RFID reader, and to evaluate the effectiveness of your design.
Evaluation can be done either using the simulation infrastructure
(described shortly), or analytically, or some combination of both.
(Some simple analysis to triage approaches or explain
performance problems is always useful, as it helps decide what
design modifications seem likely to be improvements.)
If you want to do a purely analytic evaluation, and so entirely
avoid programming, please talk with me first.
In our version of the inventorying problem, a number of tags simultaneously
enter the field of the reader, sit there for a fixed time, and then
simultaneously depart. The problem is to obtain the EPC's from as
many of them as possible in that interval. We'll assume the reader
has no a priori information about the number of tags likely to
be in view.
All communication in this "network" is initiated by the reader -
the tags never speak unless spoken to. Because the reader doesn't know
which tags are there, it's not possible for it to send unicast
frames: to do that requires a destination address (i.e., a name for a
particular tag), and that's what it's trying to find out.
Instead, all frames sent by the reader are broadcast.
Frames cause tags to change their internal state.
The action a tag takes on receiving a frame differs depending on its current state.
The trick is to manipulate the (unknown) states of all the tags in a way that
causes just one to be in a state where it will answer a request to send its
EPC, and then to send that request.
Because the tags are primitive, they have very limited memory,
and can only do a few things. Those things
are defined by their specification and built into their hardware (and so
not modifiable by you, the designer of the reader's software).
The tags used in the simulator are based on the
EPC Class-1 Generation-2 UHF RFID Protocol specification.
(That's a local copy. The official version is linked from
this page.)
The tags implemented in the simulator are somewhat simpler.
This page gives an overview
of them, and how they differ from the specification cited.
The essential problem in inventorying the tags is collision resolution,
exactly the problem we've looked at for Ethernet and 802.11 wireless networks.
In the case of RFIDs, collisions occur because multiple tags are likely to
respond to a reader's request for EPCs.
An apparent novelty of RFID collision resolution is that it runs in the receiver,
rather than the senders, of the colliding frames.
That isn't terribly important, except that it implies that all colliders are
synchronized (by the reception times of frames from the reader) and almost certainly
have to operate homogeneously.
Basic Reader/Tag Operation
You should read the description of the simulator
and refer to the specification on which its based to gain a full understanding
of how the system operates. But here it is in a nutshell. (See Figure 6.19,
page 41 of the specification.)
Each tag has a Selected bit (SL), an Inventoried bit (INV), and an electronic
product code (EPC). Both SL and INV are initially false.
The reader sends a Select directive, allowing it to set the SL or INV bits
on some or all tags. Tags decide whether or not to set their bit depeneding
on a mask sent in the Select frame. If the mask matches some substring
of their EPC (which is a 64-bit string), they do so; otherwise they do nothing.
A mask of length 0 is matched by all tags.
The reader can also send any of three forms of Query directive.
Queries provide a window size and matching values for SL and INV.
Tags whose current SL and INV values match those in the Query frame
pick a random number from 0 to the
window size minus one. If they pick 0, they respond with an RN16 frame
containing a random number.
The random number acts like a temporary address for the tag.
If the reader gets back just one random number, it sends an ACK frame
to that random number. The tag that sent it originally recognizes it,
and responds with an EPC frame, providing the reader with its EPC.
If the next frame that tag hears is one of the Query frames,
it sets its INV bit to true (footnote, Figure 6.19 of the specification).
A Strawman Collision Resolution Scheme
A strawman collision resolution algorithm is implemented in the simulator
code. It causes each tag that has not yet been inventoried to pick
a random slot between 0 and 31. Tags respond only if they have picked slot 0.
If one tag does so, an EPC is (eventually) sent back to the reader,
and that tag stops participating.
Otherwise, there has been a collision or no tag has picked slot 0,
and no progress has been made.
Whether or not progress has been made, the reader just repeats
this scheme over and over. (It has no reason to stop. For one thing,
it can never know if it has managed to hear from all the tags. For
another, it has nothing better to do anyway.)
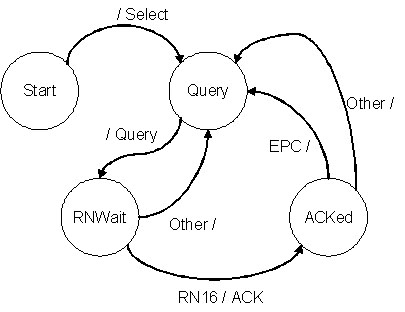
Like the tags, the reader can be thought of as a simple FSA.
Here's a picture of the strawman reader's FSA. The transition
lable A/B means "if I hear an A frame, send a B frame
and take this transition". If A is empty it means
take the transition with hearing anything, and B empty
means don't send anything. Other matches any condition
not matched by other transitions. That includes a timeout, if nothing
is heard back from the tags for long enough.
This scheme is particularly simple to analyze, so it's worth doing
because the results can tell us something about how well it can work.
If there are N tags in the reader's field, and they pick from Q slots,
the probability that exactly one picks slot 0 is N(1/Q)((Q-1)/Q)N-1.
The expected time to identify one tag, I(N,Q), is therefore the inverse,
QN/(N(Q-1)N-1).
Let T(N,Q) be the expected time to identify all tags when
N tags start in the reader's field. T(N,Q) = I(N,Q) + T(N-1,Q),
with the boundary condition T(0,Q) = 0. That isn't too useful,
except that it provides a handy way to compute T(N,Q).
Here are some results, obtained using Excel for Q = 32:
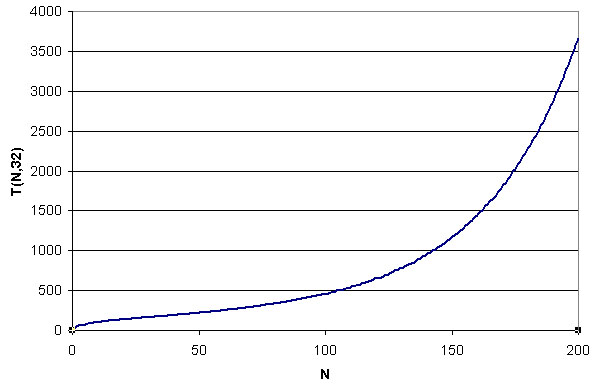
Experience with the simulator indicates our reader/tags should be able to get through
somewhere around a thousand "rounds" of the algorithm in a second, so we expect
to get pretty good results from this simple scheme for N < 125 or so.
It turns out we don't, though, indicating that something is wrong
with the analysis, something is wrong with the Excel spreadsheet,
or something is wrong with the implementation (or all three!).
Hint to help you get started: The implementation correctly
implements the FSA shown above. The Excel spreadsheet works.
The analysis is correct (although admittedly limited, in that it
uses only expectations and doesn't try to estimate the likelihood
that all tags are identified).
Independently of that, the analysis suggests that this scheme has limited
potential, because the running time is growing so fast once N
gets somewhat large.
Reiterating The Task
You have two goals. The first is to design a collision resolution
scheme the reader can use that allows it to identify "nearly all
the tags nearly the time". That is, it should be robust to
various values of N, to the bit error rate of the channel between
the reader and the tags, and to the amount of time the tags are visible
and/or bandwidth between the reader and tags (the two being the same
if we assume processing times are fast enough that all delay is
due to communication).
I expect you'll have to do a number of iterations of design and analysis
to address this first goal.
It's pretty much impossible to design the perfect scheme from scratch.
It's always possible to design a scheme that does something (e.g.,
the strawman scheme). It's hard to know if that something is good or
bad, relative to what is possible, without trying other schemes.
So, this is an iterative process.
The second goal is to support the assertion that your scheme is a good one.
This can be accomplished as a side-effect of the process above. If you've
tried a number of approaches and picked the best, that's the essence of your
assertion. (An alternative would be to "prove" some upper bound
on what any scheme could possibly achieve, and then to show that the one
you have comes close. That's harder, but a lot more convincing.)
One detail of the second goal is that you have to clearly state what you
mean by being best. Schemes will differ by how well they do with big and
small N, say. Given two schemes, neither may dominate the other
for both cases. (The same could be true of other environmental factors, like
the BER.) Picking a single scheme requires that you weigh the competing
strengths and weaknesses of the schemes.
We're most interested in how well a scheme does as N increases.
Other parameters of the simulator are the bit error rate (BER), bandwidth (BW),
and time in reader (T). The basic settings for these should be BER = 1%,
BW = 100,000 bps, and T = 1 second.
Deliverables
We're asking for both a report and your code (assuming you use the simulator).
The emphasis is on the report, though - we might not even look at the code.
To make preparing the report easier and more worthwhile, we're providing
a web interface that lets you create it as you work through your solution.
The web interface supports the notion of an evolving sequence of algorithms.
The work model it assumes is:
- I think of some basic approach, and have
enough argument why it should work that it's worth investing the time to do
some experimentation to check it out.
- I run experiments and get some results
- Based on the insights the experiments help me obtain, I either
slightly refine the basic approach and try again or scrap the basic
approach entirely in favor of another.
A web page documents a single design. Designs have major and minor
version numbers, corresponding to the small modification / wholesale rethinking
in step 3 above. Ideally, you fill in the form for an individual
version in at least three distinct steps: the "why this is worth doing"
part of the form before running experiments; the experimental results section
just after obtaining them; and finally
the post-mortem of what the results mean once you've had time to think about that.
A sample
set of reports is available.
(Okay, "will be available" - not yet up as of noon 10/15/07.)
The sample prevents you from saving
any changes, but otherwise is fully functional. I leave it to you to
decide whether the sample is A+ or D- work. Its goal, like that of
your reports, is to clearly explain to potential readers what was done,
why it was worth doing, what the results were, what the results meant,
and what was done next as a result. I don't think that should take
extremely verbose sections, but then again look at the length of this
assignment writeup...
Obtainables
Your design document web pages
Temporarily unavailable as of noon 10/15/07.
A UWNetID is required to access your pages. The first time you do so,
you should be on a page that lets you edit V1.0. After that, you
can use the buttons to move through versions, to create new versions,
and to edit versions.
The "Major Version Description" is shared across all minor versions
of the same major version. It can be editted only from the page for minor
version zero.
Simulator Javadoc
A UWNetId is required.
Most all your code goes in method sim.RFIDReader.inventory().
The Javadoc and simulator documentation
should help explain anything else you need to know.
Simulator source (V2.0)
The UWNetID protected, tar'ed, gzip'ed source, written in Java 1.5.
(Tested on attu, as well as my office Windows box (using cygwin), but should run pretty much everywhere that has Java 1.5 or
better).
It comes with a makefile - just say make in the topmost directory
to build. (You might want to say make clean;make occasionally, as I'm
not a Java programmer, and don't really understand Java's build process, which
seems to interact flakily with make at times, or at least my makefiles.)
To run, say something like this:
java -cp . sim/RFIDSim 300 20 .01 100000 1000
The command line arguments are explained in a comment preceding sim.RFIDSim.main() in the source
(and so are in the Javadoc as well).
EPC Class-1 Generation-2 UHF RFID Protocol Specification
Simulator Description
Turn-In Procedures
- Report
Your report is being turned in as you write it.
Nothing more is required for turn-in.
Because we cannot guarantee that the backend server
will not crash or otherwise lose your reports, please print a copy of
each page as you modify it.
This is just for backup; you don't have to turn in these pages unless
we notify you that the unexpected has happened.
- Code
- Condense any file(s) that you made changes to into either a .zip or .tar file format.
- Please name your file package using the format (firstname)_(lastname)_461hw4_(your section) so that it is easier for the TA's to grade.
- To make a tarball on a UNIX machine, use the command "tar cf (filename) (file #1) (file #2) (file #3) ..." in the directory containing your files. (c means create a new .tar, f means that the next argument will be the name of the file to create, and the remaining arguments should be the names of your files.
- You can go back and modify your submissions up to the due date (11:59pm next Wed).
- Submit your code via
catalyst
with your myuw netid.
Grading
In most circumstances we'll be grading exclusively on the contents of
the web-submitted version documentation. We'll look at the code only
if what you've said is particularly interesting or particularly suspicious.
Grading will be oriented towards process, rather than focusing exclusively
on results. Your version documentation should show that you're learning
things, are putting some thought into understanding why what you're observing
is occuring, and making good decisions about what is worth trying next and what
isn't. You don't have to have the best scheme possible to earn full credit.
On the other hand, if what you're observing is completely impossible for
a correct implementation of the scheme you claim it comes from, and you
don't notice that, that's both simply a bug in your code and
a definite negative regarding your grade.
Optional Extra-Credit
(The extra credit is small, and shouldn't be a reason to try to do this.)
Do any or all of these:
- Design and evaluate schemes that control two readers simultaneously
inventorying the same set of tags.
- Let's define three classes of 2-reader algorithms.
In the first, identical code (including all parameter settings) run
independently in the two readers.
In the second, identical code but different parameter settings run
in them.
In the third, the two run different code.
How much benefit is gained as you move from from each class to the next?
(Is there any motivation to think about non-homogeneous solutions to
the two reader problem?)
- Change the simulator's link layer specification in ways that allow faster
and/or more accurate inventorying. Your changes should be plausible -- don't
inject something no real tag could do. (You could add new directives/frames,
for instance, so long as what the tag had to do was simple.)
The first of these undoubtedly requires introducing sessions
(as described in the spec) into the simulator. That should be very simple.
I think of the second as more of a theory problem than something one
would address by simulation, although some insight might be possible
from specific simulator experiments.
I think it's unlikely you'll find a breakthrough for the third option (with
the possible exception of something that is in the real spec but I left
out of the simulator). The committee designing the real spec has a lot
of knowledge, and time to work things out.
|
