
Average Face
10 Eigenfaces (in decreasing order)










Smiling Student Recognition Rates
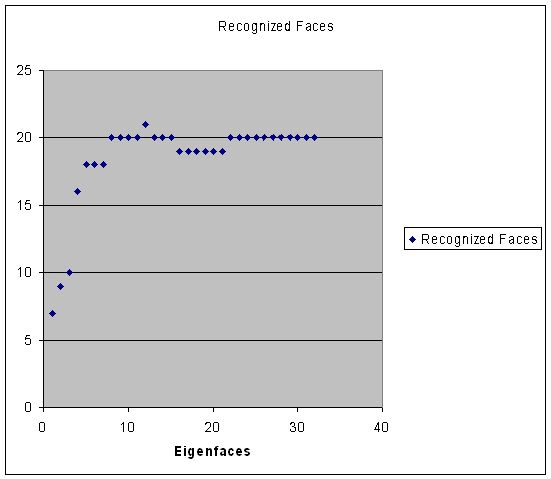
Describe the trends you see in your plots. Discuss the tradeoffs; how many eigenfaces should one use? Is there a clear answer?
12 eigenfaces netted the highest recognition rate of 21/32 faces.
There is an early and significant increase in the recognition rate from 1 to 5 eigenfaces, beyond that there is continued slow growth until 8 eigenfaces.
The data suggests that there is a small number of eigenfaces for which additional eigenfaces do not improve recognition rates.
You likely saw some recognition errors in step 3; show images of a couple. How reasonable were the mistakes? Did the correct answer at least appear highly in the sorted results?
There were several recognition errors. Sometimes I could almost explain them, if both people have glasses and a moustache and their head titled the same way:


But other times...


George The Lesser gets cropped...
[0.25 0.55 0.01]


I get cropped in Australia...
[0.30 0.40 0.01]


Finding classmates...
[0.45 0.55 0.01]


Finding other people...
[0.30 0.36 0.01]


What min_scale, max_scale, and scale step did you use for each image?
See the text accompanying each image: [min_scale max_scale step].
My general algorithm for finding a scale was to extimate the size of a face in pixels (in N pixels square) and then take the 25 pixel square eigenfaces I am using and divide that by the estimated face size.
I'd then take a range around that value. If, for example, faces are about 70 pixels square then 25/70=.36 => .30 to .40.
Did your attempt to find faces result in any false positives and/or false negatives? Discuss each mistake, and why you think they might have occurred.
Yes, I had ... 1.5 false negatives in the Seinfeld photo. I can't explain why the algorithm found the particular "faces" it did, but I might be able to provide some reasons as to why it missed the faces that are actually present.
Firstly, Kramer and Jerry have taller, more oblong faces than do George and Elaine. If you look at the average face, it's rather round, much more like George and Elaine than Jerry or Kramer.
I wonder whether grouping all faces together and deriving a single average and set of eigenfaces is the best algorithm. Perhaps faces could be classified (tall/thin, short/round, by skin type, by hair, etc.) and a set of eigenfaces employed for each class.
This might allow a class to vary greatly from the "universal" average and thereby match a set of faces that were otherwise missed.
Secondly, the two missed faces are each tilted (although in opposite directions). Since there is no freedom for rotation in the algorithm, this could easily throw off the results.
Check out Image(int,int). Unlike the other Image(int width, int height, ...) constructors, this one is Image(int height, int width). It took me a good while to figure that one out. Swapping the width and height was causing my boxes to be too tall and thin, and to not center on the faces as expected.
I don't like the algorithm for keeping track of potential face matches. The main thing I don't like is that I don't believe it is optimal.
Imagine that you had two sets of matches a1...aI which are greater matches than b1....bJ. As you progress through the search, a1...aI totally fill the set of
matches that you're keeping track of. Then, the last face you attempt to recognize is aX which is a better match than each of a1...aI and overalps them all
as well. You put aX in your list, and remove a1...aI from your list. Too bad you've now only got one face when you were looking for more. Wouldn't it be nice
to still have b1...bJ around?
Well, maybe I just have a weak implementation of whatever algorithm you were hinting at, but in my case I chose the arbitrary bound of 4*n for my list of faces (where
n is the number of faces I'm searching for). It seems to be working just fine in practice.
I changed isFace to not return the MSE exactly. It returns the MSE scaled by the magnitude of the face less the average face, and then divided by the variance. These changes were suggested in the project description. Since making these changes, I've had relatively little problem with finding "faces" in low-texture areas.
I changed the output of --recognizeFace to put both the known and unknown filenames on the same line. That way I could use grep to easily match which ones it got right.
I do output a debug.tga, but it's not horribly useful. It can show you the general areas where faces were being found, but the normalization is off so it's hard to distinguish between good faces and less-good faces.
There is at least one magic constant in my code; 1000 is the cutoff for isFace. All "correct" faces that I was finding seemed to be below that threshhold.