For the 2000 calendar year, the USENIX Association granted me a scholarship to support my graduate studies in the development of compiler technology for parallel computing. I was (and remain!) very grateful for this support and have assembled this page to report on the work that was done as a result of this scholarship.
ZPL is a data parallel array programming language that has been under development at the University of Washington during the past decade. ZPL differs from other parallel programming languages in that it supports a global-view of parallel programming, yet allows programmers to understand the parallel implementation of their algorithms simply by inspecting their source code.
We're currently in the process of evolving ZPL into its successor language, Advanced ZPL (A-ZPL). This language will support more general types of parallel computation including task parallelism, pipelined parallelism, and irregular data structures. My particular interest for the short-term is to support sparse hierarchical applications such as Adaptive Mesh Refinement (AMR) and the Fast Multipole Method (FMM). With the support of the USENIX scholarship, I was able to complete some of the initial work in this area during the past year. The accomplished tasks break down into three rough areas: (1) developing support for multigrid algorithms in ZPL, (2) developing support for sparse arrays and computation in A-ZPL, and (3) supervising student qualifying projects that implemented optimizations helpful for both application areas.
The first half of my work under the USENIX scholarship was to implement multiregions, multiarrays, and multidirections in the ZPL compiler. These concepts ease the programmer's task in creating parallel multigrid algorithms such as the one used in the NAS MG benchmark.
To evaluate our implementation, we compared the ZPL implementation of NAS MG against versions written in several other parallel programming languages: Single-Assignment C (SAC), High Performance Fortran (HPF), and Co-Array Fortran (CAF) as well as the original F90+MPI implementation by NAS. Each of these benchmarks was written by someone well-versed in the language, in most cases the language developers themselves.
In a paper published at SC2000, we compared the benchmarks in terms of expressiveness, portability, and performance. While all of the languages did reasonably in one or two of these areas, ZPL was the only language to do well in all three arenas. The following graphs give some indication of our expressiveness and performance (click on graph to get full-size view):
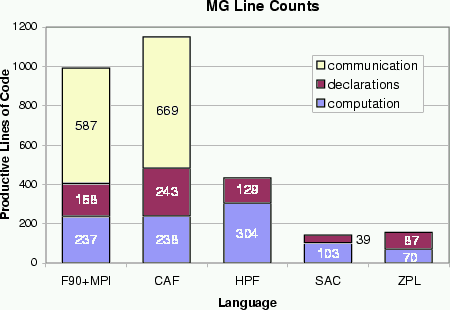
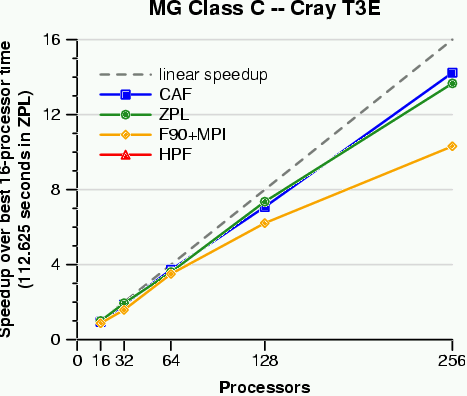
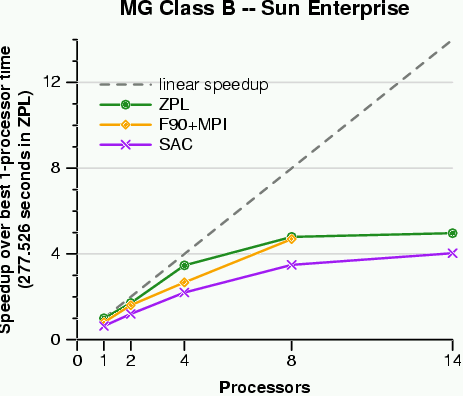
These graphs indicate that ZPL is able to achieve performance that's competitive with the fastest language on each machine, using a fraction of the number of lines of code. In fact, the ZPL code is not only shorter, but also much clearer. The following Venn diagram summarizes the results of our study:
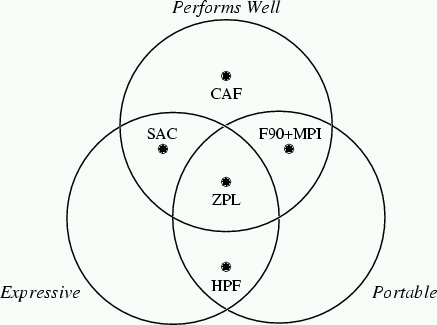
These language features are available in the current release of the ZPL compiler.
The next step was to support sparse computation in A-ZPL. The goal of this work was to preserve ZPL's benefits -- its clear syntax, global-view of parallel programming, syntax-based performance model, and good performance -- within the context of sparse array computation and sparse computation over dense arrays. This work is still underway, but got off to an extremely promising start under the USENIX scholarship.
For our preliminary study, we wrote sparse versions of the NAS CG and NAS MG benchmarks in A-ZPL and compared the results to the original F90+MPI versions. For this initial study, the goal was to see whether our general compiler-implemented sparse representation could compete with a customized hand-coded sparse representation (NAS CG). We also studied whether it could be used to effortlessly introduce sparsity into a traditional dense code (NAS MG) and improve both performance and memory utilization. Our conclusion for both experiments was that it could. The results of this study were written up and submitted to the USENIX 2001 Annual Technical Conference. The following graphs summarize some of our results:
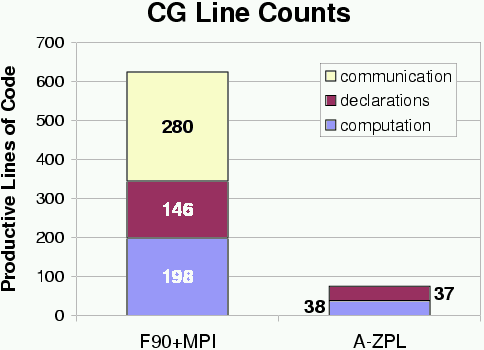
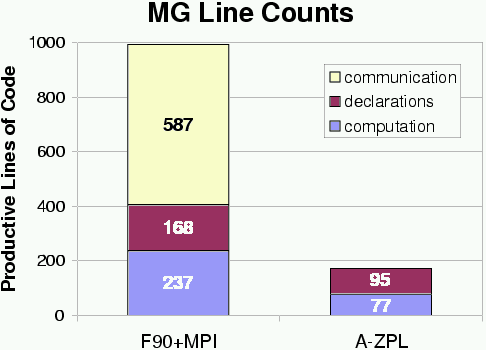
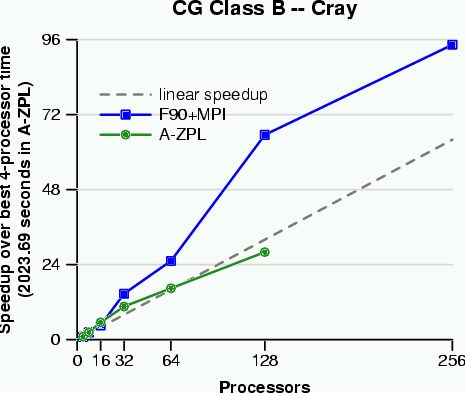
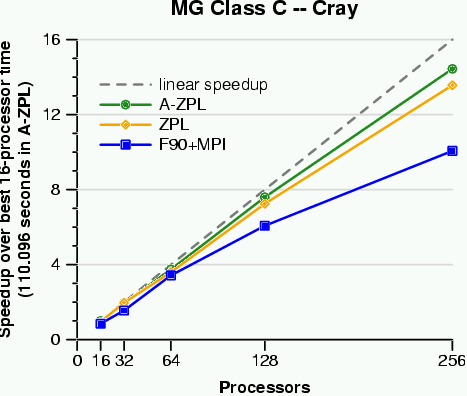
The NAS CG graphs show that while A-ZPL is not yet able to compete with a hand-coded customized sparse representation, it still achieves near-linear performance, and requires a much smaller programming effort on the user's part. The NAS MG graphs indicate that selective uses of sparsity can be added to a dense application with a minimal amount of programmer effort and a tangible benefit in performance (and memory usage). These language features will be available in the next release of the ZPL compiler.
The third component of my work under the USENIX scholarship was to co-advise two graduate students during their qualifying projects. Each student chose an optimization to perform in the ZPL compiler, implemented it, and studied its impact. The first optimization, developed by Maria Gullickson, hoists loop-invariant code generated by ZPL's flood dimensions out of inner loops. This optimization benefits parallel codes that use problem space promotion, including the NAS CG benchmark above.
The second optimization, performed by Steven Deitz, reorganizes stencil operations on arrays to eliminate redundant computation and memory references. This optimization made a big difference in our performance for the NAS MG benchmark above. We wrote this work up and submitted it to PLDI '01.
Both of these optimizations are included in the current release of the ZPL compiler.
With the help of the USENIX scholarship, I was able to make good progress toward supporting sparse hierarchical applications in A-ZPL without sacrificing ZPL's advantages. The next step in this work is to optimize our sparse array implementation even further. At that point, we will be ready to combine the hierarchical arrays of the multigrid method with our sparse arrays to achieve the sparse hierarchical computation that we set out to achieve.
Once again, I'd like to offer my deep thanks to the USENIX Association for providing this scholarship. It was an invaluable help to my progress this past year.