
A complete list of our research projects may be found on the GRAIL Research Projects page.
Verification Games

Our goal is to make verification more cost-effective by reducing the skill set required for program verification and increasing the pool of people capable of performing program verification. The approach is mapping a program verification problem into a game. When the game is solved, the final configuration of board elements can be mapped into a proof of correctness of the original program.
Collection Flow

Computing optical flow between any pair of Internet face photos is challenging for most current state of the art flow estimation methods due to differences in illumination, pose, and geometry. We show that flow estimation can be dramatically improved by leveraging a large photo collection of the same (or similar) object. In particular, consider the case of photos of a celebrity from Google Image Search. Any two such photos may have different facial expression, lighting and face orientation.
Face Reconstruction in the Wild

We address the problem of how to reconstruct 3D face models from large unstructured photo collections, e.g., obtained by Google image search or from personal photo collections in iPhoto. This problem is extremely challenging due to the high degree of variability in pose, illumination, facial expression, non-rigid changes in face shape and reflectance over time and occlusions. In light of this extreme variability, no single reconstruction can be consistent with all of the images.
Exploring Photobios

We present an approach for generating face animations from large image collections of the same person. Such collections, which we call photobios, sample the appearance of a person over changes in pose, facial expression, hairstyle, age, and other variations. By optimizing the order in which images are displayed and cross-dissolving between them, we control the motion through face space and create compelling animations (e.g., render a smooth transition from frowning to smiling). Used in this context, the cross dissolve produces a very strong motion effect.
Foldit: The Protein Folding Game

Foldit is a game designed to tackle the problem of protein folding. Proteins are small "machines" within our bodies that handle practically all functions of living organisms. By knowing more about the 3D structure of proteins (or how they "fold"), we can better understand their function, and we can also get a better idea of how to combat diseases, create vaccines, and even find novel biofuels.
(Faculty: Popović)
PhotoCity

PhotoCity is a game for reconstructing the world in 3D out of photos. Players take pictures of building exteriors from all different angles, which are then used to automatically generate 3D models and calculate virtual ownership of the buildings.
(Faculty: Popović)
Being John Malkovich

Given a photo of person A, we seek a photo of person B with similar pose and expression. Solving this problem enables a form of puppetry, in which one person appears to control the face of another. When deployed on a webcam-equipped computer, our approach enables a user to control another person’s face in real-time.
Shape-Based Retrieval of 3D Craniofacial Data

The goal of this work is to provide tools for the study of craniofacial anatomy from either CT scans or from a 12-camera active stereo photogrammetry system. Our image-analysis tools provide low-level operators for working with 3D craniofacial data. Our feature extraction tools produce quantitative representations (descriptors) of the 3D data that can be used to summarize the 3D shape with respect to the condition being studied and the question being asked.
Multimedia Information Retrieval

Scientific research in the biological domain generates massive amounts of data of many different kinds. With a hypothesis to investigate, researchers run large numbers of experiments that use data from human and animal subjects and produce multiple outputs of different modalities, ranging from simple textual data to signal, image, and 3D volumes, such as CT and MRI scans. Despite the massive scale and complexity of this data, many researchers at the forefront of biological sciences are using antiquated methods for storing their multimedia data.
Image Segmentation for Camera Phones

Among the many problems in image editing, cutting out an object is a very important task. Directly applying algorithms targeted for desktops to mobile phones does not yield the desired performance and user experience. This project supports the development of interactive, real-time algorithms for mobile phone image segmentation.
(Faculty: Shapiro)
Pattern Recognition for Ecological Science and Environmental Monitoring

The goal of this project is to develop a highly automated approach to the classification of insect specimens. It includes the development of computer vision and machine learning algorithms for automatic classification of insects from images according to family, genus, and species. It also involves designing and building a mechanical device that can transport insects through the field of a microscope and automatically photograph them.
Biomedical Imaging and Informatics

This project involves ongoing collaborative research with the Biomedical and Health Informatics program at the UW Medical School. Projects include the construction of 3D models from image data, the automatic classification and retrieval of body-part images, the creation of a reference ontology for the human body, and query systems to access this data.
(Faculty: Shapiro)
Content-Based Image Retrieval
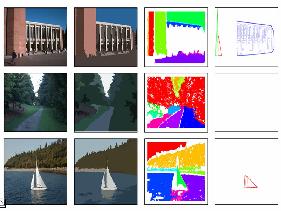
The goal of this research is to develop the necessary methodology for automated recognition of generic object and concept classes in digital images. The work builds on existing object-recognition techniques in computer vision for low-level feature extraction and designs higher-level relationship and cluster features and a new unified recognition methodology to handle the difficult problem of recognizing classes of objects, instead of particular instances. Local feature representations and global summaries that can be used by general-purpose classifiers are developed.
The Dimensionality of Scene Appearance

Low-rank approximation of image collections (e.g., via PCA) is a popular tool in many areas of computer vision. Yet, surprisingly little is known to justify the observation that images of an object or scene tend to be low dimensional beyond the special case of Lambertian scenes.
Reconstructing Building Interiors from Images

This project (and related paper) propose a fully automated 3D reconstruction and visualization system for architectural scenes (interiors and exteriors). The reconstruction of indoor environments from photographs is particularly challenging due to texture-poor planar surfaces, such as uniformly-painted walls.
Parallax Photography: Creating 3D Cinematic Effects from Stills

We present an approach to convert a small portion of a light field with extracted depth information into a cinematic effect with simulated, smooth camera motion that exhibits a sense of 3D parallax. We develop a taxonomy of the cinematic conventions of these effects, distilled from observations of documentary film footage and organized by the number of subjects of interest in the scene. We present an automatic, content-aware approach to apply these cinematic conventions to an input light field.
Community Photo Collections

With the recent rise in popularity of Internet photo sharing sites like Flickr and Google Images, community photo collections (CPCs) have emerged as a powerful new type of image dataset for computer vision and computer graphics research. With billions of such photos now online, these collections offer huge opportunities in 3D reconstruction, visualization, image-based rendering, recognition, and other research areas.
Manhattan-World Stereo

Multi-view stereo (MVS) algorithms now produce reconstructions that rival laser range scanner accuracy. However, stereo algorithms require textured surfaces and therefore work poorly for many architectural scenes (e.g., building interiors with textureless, painted walls).
Enhancing and Experiencing Spacetime Resolution with Videos and Stills

We present solutions for enhancing the spatial and/or temporal resolution of videos. Our algorithm targets the emerging consumer-level hybrid cameras that can simultaneously capture video and high-resolution stills. Our technique produces a high spacetime resolution video using the high-resolution stills for rendering and the low-resolution video to guide the reconstruction and the rendering process.
Layered Depth Panoramas
Representations for the interactive photorealistic visualization of scenes range from compact 2D panoramas to data-intensive 4D light fields. Our research proposes a technique for creating a layered representation from a sparse set of images taken with a hand-held camera. This representation, which we call a layered depth panorama (LDP), allows the user to experience 3D by off-axis panning. It combines the compelling experience of panoramas with limited 3D navigation. Our choice of representation is motivated by ease of capture and compactness.
Crowd Flows

Human crowds are ubiquitous in the real world, making their simulation a necessity for realistic interactive environments. We present a real-time crowd model based on continuum dynamics. In our model, a dynamic potential field simultaneously integrates global navigation with moving obstacles, such as other people, efficiently solving for the motion of large crowds without the need for explicit collision avoidance.
Model Reduction of Complex Dynamics

Computer graphics researchers have made great strides towards the simulation of complex phenomena for special effects and other off-line applications. A much less explored but equally important domain is interactive virtual worlds, including training simulations, computer games, and other situations where interactivity is required. This project explores the use of model reduction to achieve drastically faster simulations of complex, high-dimensional phenomena. Our current work focuses on incompressible fluids.